
模型量化(quantization)指的是用更少的bit表示模型参数,从而减少模型的大小,加速推理过程的技术。
模型量化是把模型的参数从FP32映射到nbit位的过程, 简单来说就是在定点数与浮点数等数据之间建立一种数据映射关系, 使得以较小的精度损失代价获得了较好的收益。 例如FP32-->INT8可以实现4倍的参数压缩,在压缩内存的同时可以实现更快速的计算,从而有效地提高模型的性能; 最极端的二值量化理论上甚至可以实现32倍的压缩,但是过度的压缩会导致模型的精度快速下降, 所以更多量化的时候需要做好精度和性能的权衡.
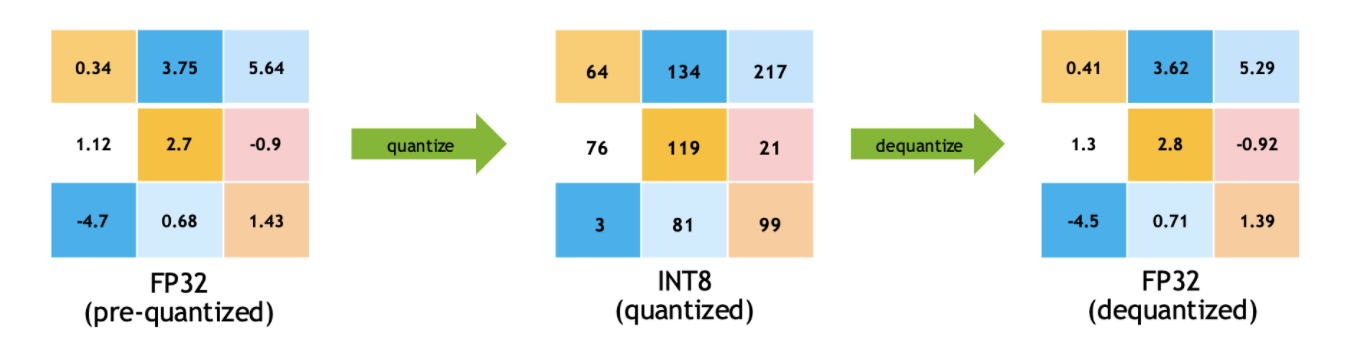
工业界一般使用int8量化, 在模型推理前需要把FP32映射为int8进行计算, 然后在输出的时候做一个去量化操作, 把计算的int8结果映射回FP32.
关于量化的3个问题:
为什么不直接训练一个低精度的网络? 一般训练使用的是梯度下降法, 直接用 定点数做参数训练很容易导致梯度消失, 训练的模型会欠拟合, 所以训练阶段我们还是要用 浮点数 来做参数.
为什么可以做量化? 神经网络模型一般有较好的抗干扰能力对噪声不敏感,量化相当于对原输入加入了大量的噪声, 对模型的精度一般不会造成太大影响.
为什么用低精度数量化后性能可以提升? 首先我们要知道一点就是: 模型的性能主要由模型的参数量和计算量来决定的. 参数量的大小直接决定模型的大小,也影响推断时对内存的占用量以及内存的访问次数. 很多时候模型计算需要内存和CPU共同协作, 同一个计算量下, 模型越大内存占用就越大内存访问次数也就越多, 而我们知道CPU和内存的速度根本就不在一个数量级, 所以模型的参数量大小一般决定了模型性能的下限.
计算量越大的模型, 性能一般越差, 我们知道CPU或者GPU的FLOPS(每秒浮点计算量)是相对固定的, 模型的计算量大小是决定了模型性能的上限.
模型量化作用
减少内存带宽和存储空间
提高系统吞吐量(throughput),降低系统延时(latency)
易于在线升级,模型更小意味着更加容易传输
减少设备功耗,内存耗用少了推理速度快了自然减少了设备功耗
支持微处理器,有些微处理器属于8位的,低功耗运行浮点运算速度慢,需要进行8bit量化