
从 Claude Code 源码里,我看到了下一代 Agent 的真正形态
不是更聪明的模型,而是更成熟的系统。
最近看了 Claude Code 源码。
npm 包里还原出的完整 TypeScript 源码, 4756 个文件。
刚看到这个数字的时候,我的第一反应不是“太夸张了”,而是:
Claude Code 已经不是一个“会写代码的 AI 工具”了。
它更像一套完整的 Agent Operating System。
它不只是一个 prompt 加几个 tool,而是一整套:
主循环与状态机
工具执行与权限治理
多 Agent 分工
上下文预算系统
长期记忆
插件与 MCP 生态
后台任务、恢复、清理、生命周期管理
真正厉害的地方,不是它会不会写代码,而是它如何让模型稳定、可控、持续地工作。
Claude Code 整体架构
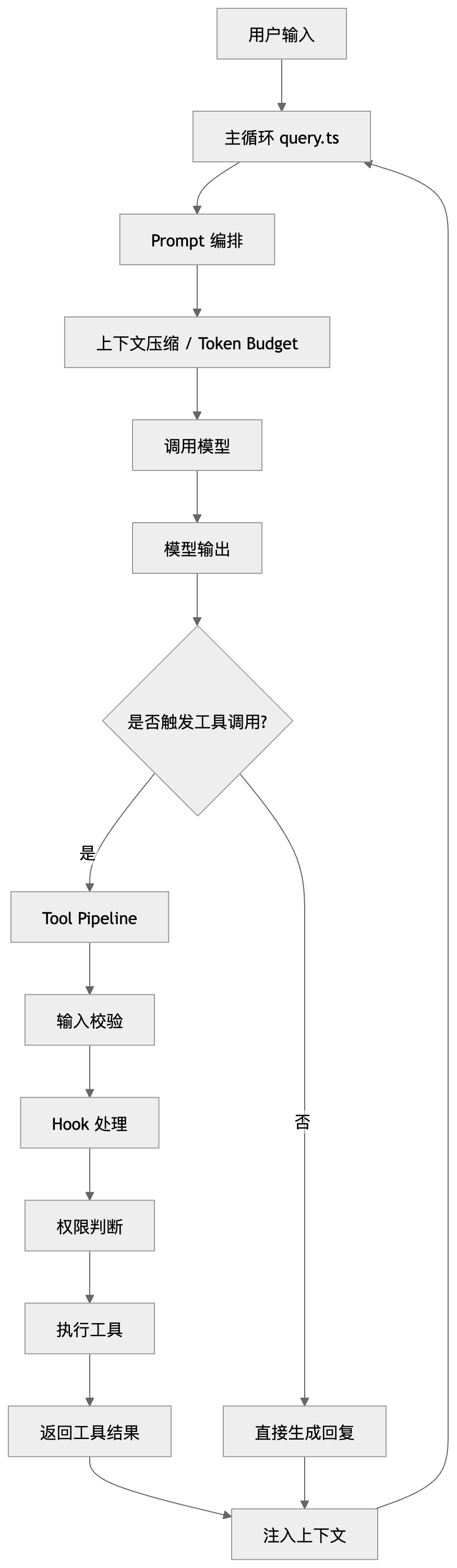
Claude Code 的核心不是一次调用模型,而是一套持续循环的 Agent Runtime。
工具执行 Pipeline
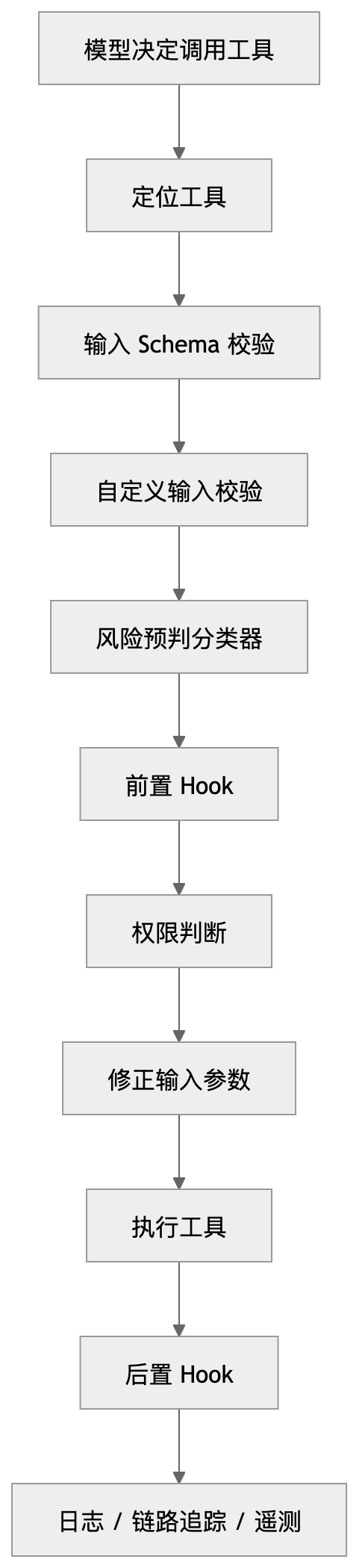
Claude Code 最成熟的地方,不是工具多,而是每次调用都经过完整治理。
多 Agent 分工

多 Agent 的意义,不是更聪明,而是把“探索、实现、验收”彻底拆开。
Claude Code 的三层安全网
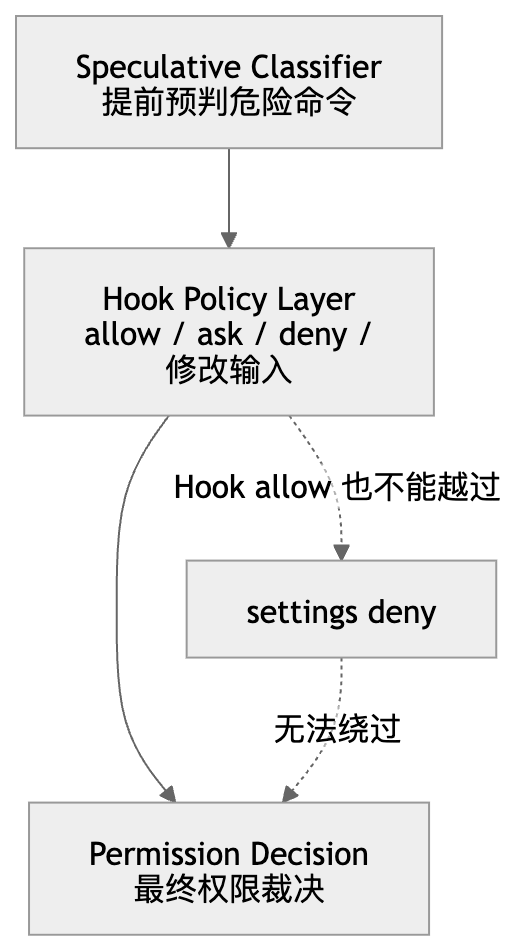
安全最厉害的地方,不是有多少层,而是每一层都不能绕过另一层。
上下文预算系统
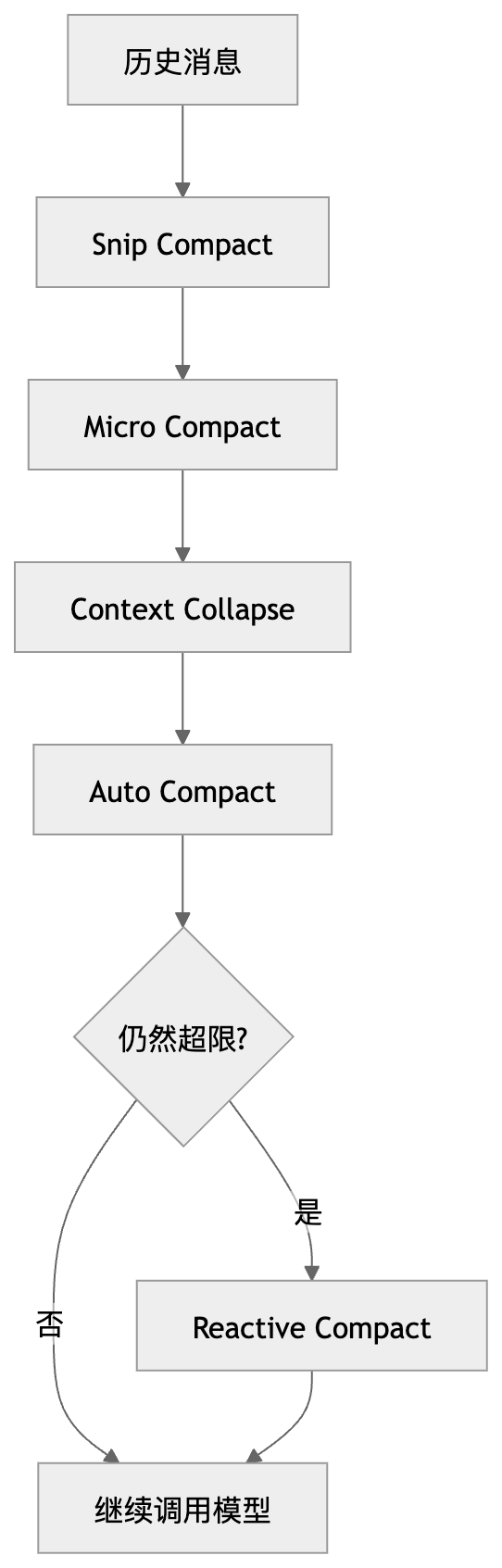
Claude Code 不把上下文当仓库,而是把它当成一种预算。
为什么 Claude Code 看起来像一个“操作系统”
很多 AI Coding 产品,打开源码后你会看到:
一个 main
一个 prompt
几个 tool
一些 util
但 Claude Code 的顶层目录已经完全不是这个规模,其核心模块包括:
commands/
tools/
services/
hooks/
skills/
tasks/
bridge/
memory/
permissions/
compact/
其中几个核心文件的规模非常夸张:
这意味着它已经不是“写几个 prompt 驱动模型”,而是在认真构建一套长期运行、可恢复、可治理的 Agent Runtime。
我觉得可以把 Claude Code 理解成这样一层架构:
用户输入
↓
主循环(query.ts)
↓
Prompt 编排 + 上下文预算
↓
模型输出
↓
工具执行 Pipeline
↓
权限 / Hook / 安全检查
↓
结果注入下一轮
↓
继续循环,直到任务完成
它真正的核心不在模型,而在“模型之外”。
Agent 的本质,不是一轮问答,而是一个状态机
Claude Code 最重要的文件之一,是 query.ts。
它并不是简单地:
1.收到用户输入
2.调一次模型
3.输出结果
而是内部维护了一个 while(true) 的主循环。
每一轮都会经历:
1.压缩上下文
2.检查 token 预算
3.拼接 system prompt
4.调模型 API
5.流式解析输出
6.执行工具
7.注入结果
8.判断是否进入下一轮
这个设计特别重要。
因为 Agent 真正面对的问题,不是“第一次能不能答出来”,而是:
上下文太长怎么办?
工具调用失败怎么办?
模型输出到一半超限怎么办?
一轮没做完,要不要继续?
某个步骤失败后,应该从哪里恢复?
很多 AI Demo 都能完成第一轮,但一进入长任务、多步骤、复杂上下文,就会开始崩。
Claude Code 的做法,是把整个过程设计成一个可恢复、可继续、可重试的状态机。
换句话说:
Prompt 决定模型“怎么说”,主循环决定系统“怎么活”
它把 Prompt 从“一段话”变成了一套装配系统
Claude Code 里最有意思的一点,是它的 system prompt 并不是一次性拼成的大字符串。
它被拆成了很多 section。
静态部分:
- 身份定位
- 行为规范
- 工具语法
- 风格要求
- 风险动作规范
动态部分:
- 当前会话状态
- Memory
- MCP instructions
- 当前目录、系统环境
- 语言偏好
- 当前可用工具
而且中间还有一个边界:
SYSTEM_PROMPT_DYNAMIC_BOUNDARY
为什么要这么做?
因为 Anthropic 在做 prompt cache。
如果两次请求的 system prompt 前半部分完全一致,那么 API 可以直接复用缓存。
即:
1.不会变的内容,放前面
2.会变化的内容,放后面
3.尽量让前缀保持字节级一致这个思路特别像现代 Web 的缓存设计。
以前我们会觉得 prompt 是“写得好不好”。
Claude Code 告诉我们:
Prompt 也是一种运行时资源,它需要被缓存、拆分、复用、按需加载。
真正成熟的工具系统,不是“模型想调就调”
Claude Code 一共有 42 个工具。
但比工具数量更重要的是:它有一条完整的工具治理流水线。
当模型决定调用一个工具时,它不会直接执行。
而是要先经过:
找到工具
→ 输入 schema 校验
→ 自定义输入校验
→ 风险分类
→ 前置 Hook
→ 权限判断
→ 修改输入
→ 真正执行
→ 后置 Hook
→ 记录日志和追踪这个设计非常重要。
因为一旦模型开始能:
改文件
跑 Shell
调数据库
操作浏览器
调用外部系统
你就已经不再是在做聊天机器人,而是在做一个具备执行能力的软件代理。
这时候,如果没有治理层,系统迟早会翻车。
Claude Code 有几个特别值得学习的细节。
1. 默认 fail-closed
如果一个新工具忘了声明“是否只读”,系统默认它会写。
如果忘了声明“是否并发安全”,系统默认它不安全。
即:
忘了配置,就按最严格处理。
这是一种非常典型、也非常成熟的安全思维。
2. Shell 工具会提前做风险预判
比如 BashTool。
在正式弹权限框之前,它就已经启动了一个风险分类器,提前判断:
rm -rf 是否危险
curl | bash 是否危险
某个命令是否可能破坏系统
而且这个风险判断和 Hook、权限检查是并行进行的。
最终用户感觉到的,是系统响应更快了。
本质上,它是在利用“等待模型输出的时间”去提前做风险分析。
这是一种很典型的工程优化。
多 Agent 最重要的价值,不是更聪明,而是分工
现在很多产品都在讲 Multi-Agent。
但 Claude Code 的多 Agent,我觉得是少数真正讲清楚“为什么要多 Agent”的案例。
它至少有几种角色:
Explore Agent:负责探索
Plan Agent:负责规划
General Agent:负责执行
Verification Agent:负责验证
为什么要拆开?
因为一个 Agent 同时做:
研究
规划
实现
验收
最后往往每一件事都做不好。
最典型的是:实现者很容易高估自己。
它刚写完代码,就会下意识觉得“应该没问题了”。
所以 Claude Code 专门设计了一个 Verification Agent。
它的任务只有一个:
想办法把前面那个 Agent 写的东西搞坏。
它会被要求:
真正去运行
真正去点击
真正去 curl
真正去验证 stdout / stderr
真正记录命令和结果
最后只能给出:
PASS
FAIL
PARTIAL
它甚至还专门防止模型偷懒。
比如:
“代码看起来没问题”
“测试大概能过”
“这个应该没事”
这些都不算验证。
Claude Code 会直接要求:
别猜,去跑。
我觉得这是这套系统最有价值的地方之一。
因为 AI 最容易犯的错,从来不是“不会”,而是“差不多”。
安全设计最厉害的地方:每一层都不能绕过另一层
Claude Code 的安全层一共有三层:
风险分类器
Hook
权限决策
其中最成熟的一点是:
它们互相协作,但互相不能绕过。
比如:
Hook 说 allow
但配置文件里写了 deny
最终还是 deny。
再比如:
Hook 可以修改输入
但不能让一个危险命令静默通过
这套设计的价值在于:
即使某一层写错了,系统也不会整体失控。
很多产品的问题恰恰相反。
插件系统一强大,安全边界就被打穿了。
Claude Code 的做法是:
Hook 可以很强,但不能越权。
这是一个成熟系统最重要的特征之一。
真正的插件系统,不是“接进来”,而是“让模型知道它存在”
Claude Code 支持:
Skill
Plugin
MCP
但它和很多系统最大的不同在于:
它不只是把工具接进来。
它还会把:
工具说明
Skill 描述
MCP instructions
当前有哪些能力
什么时候该用
全部注入给模型,模型会知道:
“我现在有哪些工具,以及什么场景应该用它们。”
这一点其实特别关键。
很多系统明明接了十几个插件,但模型不知道什么时候该调用。
于是插件虽然存在,但等于不存在。
Claude Code 真正厉害的地方,是它让模型“感知到”自己的能力。
生态的最后一公里,不是工具接入,而是能力可见。
Token 不只是长度,而是一种预算
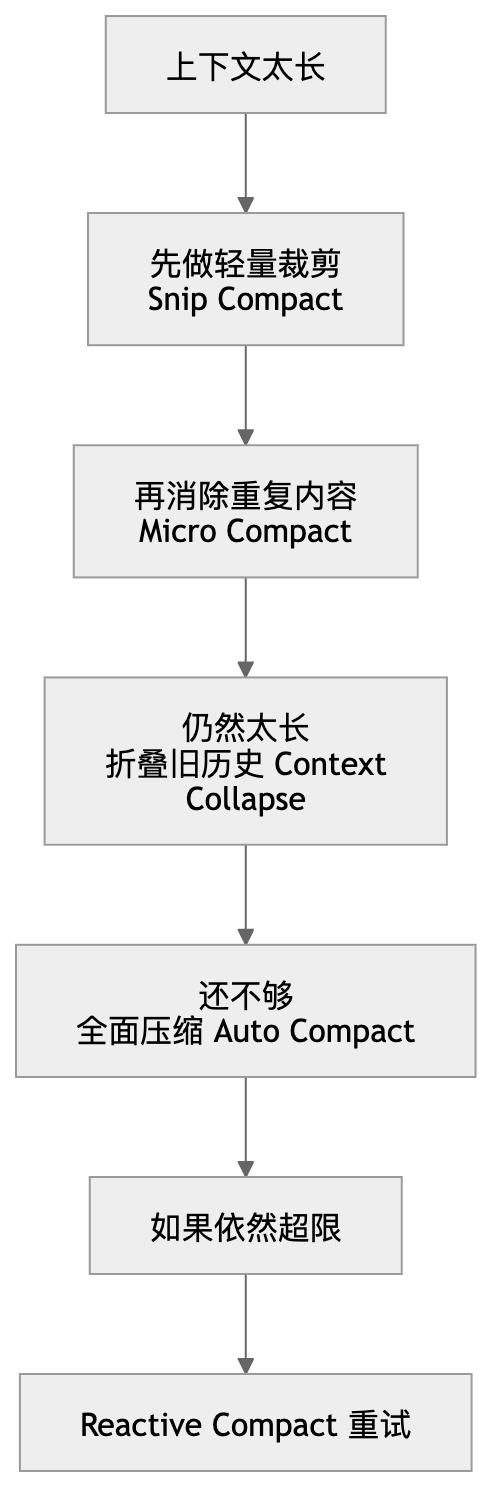
Claude Code 对上下文的处理方式,也特别值得学习。它没有简单地“超了就截断”,而是有四层压缩机制。
四层压缩机制
1.Snip Compact:剪掉历史里最不重要、最长的部分
最轻的一层。
它不会改动整个上下文,只会把特别长、特别旧、又不太重要的消息尾部裁掉,比如:
很长的日志
很长的文件 diff
很长的工具输出
很久以前的回复
例如原本:
Tool Output:
...
第 1 行
第 2 行
...
第 500 行Snip Compact 可能会变成:
Tool Output:
第 1-20 行
...
[省略 460 行]
...
第 481-500 行它只是“剪掉冗余部分”,上下文结构和原意还保留着。
适合解决:
工具输出太长
某一条消息特别占 token
2.Micro Compact:只压缩被重复引用、重复出现的内容
比 Snip 更聪明一点。
Claude Code 里很多 tool_use / tool_result 会反复在后面被引用。Micro Compact 不会重新总结整段,而是:
找到之前已经出现过的工具结果
用一个更短的引用或摘要替换
只保留后续真正新增的内容
比如原本连续几轮里都带着:
之前 FileRead 读取了 a.ts 的完整内容后面可能会变成:
引用 FileRead#42 的结果(a.ts 内容)或者:
沿用之前的 tool_result,仅保留本次新增 diff所以它本质上是在做:
“不要重复把同一段内容塞进上下文”
适合解决:
多轮工具调用
重复读取同一个文件
长对话里不断重复同样的信息
3.Context Collapse:把一大段旧上下文折叠成摘要
这是第一次真正“总结”。
当会话已经很长,前面很多轮虽然重要,但短时间内不会直接用到时,Claude Code 会把那一整块历史折叠成一段摘要。
例如原本有十几轮:
用户先让 Agent 调查 bug
然后又读取了 6 个文件
又修改了两个函数
又跑了测试
...Collapse 后会变成:
历史摘要:
- 已确认 bug 出在 auth.ts
- 已修改 login() 和 refreshToken()
- 已跑过单元测试,仍有一个失败
- 当前剩余问题:session 超时逻辑即:
保留“发生了什么”
丢掉“具体每一句怎么说的”
这是第一次会明显损失细节,但能省很多 token。
适合解决:
长任务
多轮协作
前面做过很多事情,但只需要记住结论
4.Auto Compact:真的快超上限时,强制做一次全面压缩
这是最后一道、最重的一层。
当前面几层都还不够时,Claude Code 会主动触发一次“全量压缩”。
它会:
大规模总结历史
只保留当前任务最关键的信息
把旧的 tool output、长日志、长 diff 都折叠掉
甚至可能只留下“当前状态”和“下一步”
比如原来 10 万 token 的上下文,压到只剩:
当前任务:
修复支付失败问题
当前状态:
- 已确认问题在 retry 逻辑
- payment.ts 已修改
- 剩余:验证 timeout 场景
重要文件:
- payment.ts
- retry.ts它更像是:
“把整个会话重新浓缩成一份工作备忘录”
因为压缩很重,所以 Claude Code 会尽量先尝试前面三层;只有真的快撞到模型窗口上限时,才会触发 Auto Compact。
快速理解
可以把四层理解成下面这个层级:
Snip Compact = 剪掉一点边角料
Micro Compact = 不重复讲已经讲过的内容
Context Collapse = 把旧历史压成摘要
Auto Compact = 整个会话重新浓缩成一份工作笔记其中前两层几乎不影响内容,后两层会逐渐牺牲细节来换取 token 空间。
支撑压缩运行的机制
如果上面四层压缩还是不够,还有下面四种机制。
1.Reactive Compact
最后一层“应急压缩”
前面的 Snip / Micro / Collapse / Auto 都做完之后,如果真正调用模型时还是超了 token 上限,Claude Code 才会在失败后立刻回退,再做一次更激进的压缩。
它不是提前做,而是:
“调用失败了,发现真的塞不下,那就现场再压一次。”
通常会:
继续删掉更多旧消息
把长工具输出直接变成一句话
丢掉已经不太相关的历史
只保留当前任务最关键的信息
所以 Reactive Compact 更像:
“紧急模式下的二次压缩”
一般只有在特别长、特别复杂的任务里才会触发。
2.Tool Result Summary
工具结果摘要。
很多工具返回的内容会非常长,比如:
grep找到 500 行git diff改了很多文件ReadFile读出整个文件测试日志几十 KB
Claude Code 不会把这些原始结果永远塞在上下文里,而是会生成一个更短的摘要。
例如原本:
ReadFile(auth.ts)
返回 800 行代码后面可能被替换成:
Tool Result Summary:
auth.ts 包含:
- login()
- refreshToken()
- session timeout 逻辑
- 发现 retry 判断有问题或者:
测试结果摘要:
- 12 个测试通过
- 1 个测试失败
- 失败位置:payment retry timeout也就是说,它保留“工具得出了什么结论”,不保留完整原始输出。
可以理解为:
Tool Result 是原始材料
Tool Result Summary 是摘要版工作记录
3.Session Memory
会话记忆。
这是 Claude Code 在一次长任务里维护的一份“长期状态”。
它不会记录所有聊天内容,而是只保留:
当前目标是什么
已经做了什么
哪些文件被改过
哪些问题已经解决
下一步准备做什么
比如在修 bug 的过程中,Session Memory 可能会变成:
当前目标:修复登录失败
已完成:
- 定位到 auth.ts
- 修复 refreshToken
- 测试通过
待完成:
- 检查 session timeout它更像一个“任务看板”或“工作备忘录”,用于在上下文被压缩后,依然知道:
我现在做到哪一步了?
很多时候 Auto Compact 最后保留下来的核心,其实就是 Session Memory。
4.Token Budget
Token 预算。
Claude Code 不会等上下文爆掉才开始压缩,而是一直在计算:
当前已经用了多少 token
还剩多少 token 给下一轮
工具输出还能不能继续塞
是否需要提前压缩
例如一个模型窗口是 200k token,它可能内部会留:
160k 用于历史上下文
20k 留给工具结果
20k 留给模型下一轮输出所以它实际上一直在做预算管理:
如果我现在再读取一个大文件,会不会超?
如果再加一个测试日志,要不要先压缩旧内容?
这就是为什么 Claude Code 看起来不会“突然崩掉”——因为它在每一步之前,都在做 token 预算。
快速理解
可以把它理解成:
Token Budget = 整个上下文窗口的资源分配器
Session Memory = 当前任务的长期状态
Tool Result Summary = 长工具输出的摘要版
Reactive Compact = 真超限后的紧急压缩它把 token 当成一种预算,不是所有内容都值得塞进上下文。
有些内容:
可以压缩
可以摘要
可以缓存
可以按需加载
可以只保留引用
Claude Code 最重要的一个理念是:
上下文不是知识仓库,而是工作内存。
这句话我觉得特别重要。
因为很多 Agent 后面都会死在上下文膨胀上。
它的记忆系统最成熟的一点:知道什么不该记
Claude Code 的记忆系统,不是“什么都存”。
它明确规定真正应该记住的,只有这些:
用户偏好
行为反馈
项目背景
外部系统指针
而这些东西,不应该记:
代码结构
文件路径
git 历史
当前代码里的模式
因为这些都可以重新从代码里推导出来。
如果硬塞进记忆,只会越来越乱、越来越过时。
这个思路特别成熟。
真正有价值的记忆,应该是:
不可推导、但未来还会再次需要的信息。
比如:
用户讨厌某种写法
某个项目里有一个很隐蔽的坑
某个服务虽然能调用,但有已知问题
我从 Claude Code 身上学到的 7 条原则
最后,我觉得 Claude Code 最值得抄的,不是具体实现,而是背后的方法论。
1. 不要相信模型会“自己做对”
你希望它先读代码、不要乱改、不要乱加功能,就必须写成制度。
2. 角色一定要拆开
探索、规划、实现、验证,不应该是同一个 Agent。
3. 工具必须有治理
模型不能直接碰系统能力,中间一定要有权限、校验、风险分析。
4. 上下文是一种预算
不要什么都塞进去。
5. 安全机制必须互锁
任何一层都不能绕过另一层。
6. 插件生态的关键是“能力可见”
不是你接了什么,而是模型知道自己能做什么。
7. 真正的产品化,在于处理“第二天”
第一天能跑不难。
难的是:
第二天任务怎么恢复
后台进程怎么清
状态怎么同步
会话怎么续
成本怎么追踪
这些问题不解决,再聪明的 Agent,也只是 Demo。
结语
Claude Code 最让我震撼的地方,不是它用了多强的模型。
而是它让我第一次非常清楚地意识到:
下一代 Agent 的竞争,不会只发生在模型层。
真正决定上限的,是模型之外的系统工程。
谁能更好地管理上下文、治理工具、约束行为、拆分角色、控制安全、维护生命周期,谁就更有机会做出真正能长期工作的 Agent。
模型会越来越强。
但真正把模型变成产品的,永远是系统。