
最近折腾了一阵华为昇腾 910B,目标很简单:在自己的机器上把 Qwen3.5 系列模型跑起来,而且最好还能兼容 OpenAI API、支持工具调用、支持超长上下文。
最后我选择了 vllm-ascend。
这一套下来,最大的感受是:
能跑,而且跑得不算慢(至少在 Ascend上 不算慢)
但坑也不少
很多问题不是模型的问题,而是镜像、驱动、卡型、参数组合的问题
下面放一个性能测试图:
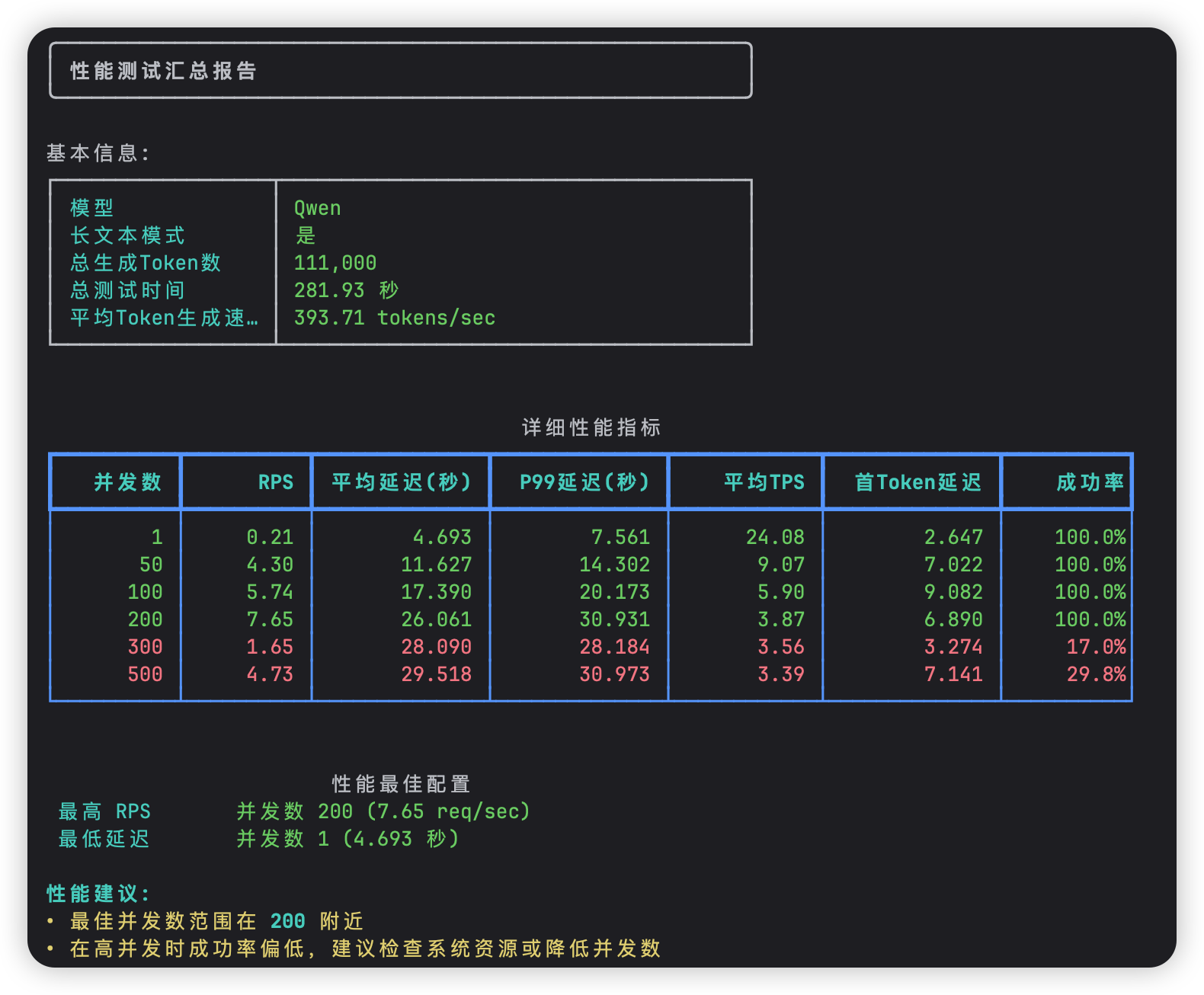
一、环境说明
我这里的环境大概是这样:
机器:华为 Ascend 910B
系统:openEuler / CentOS 类 Linux
驱动和 CANN:已经安装好
模型:Qwen3.5-27B
部署方式:Docker Compose
推理框架:vllm-ascend
先确认宿主机能看到 NPU:
npu-smi info如果能看到设备列表,说明驱动基本没问题。
例如:
+------------------------------------------------------------------------------------------------+
| npu-smi 25.2.1 Version: 25.2.1 |
+---------------------------+---------------+----------------------------------------------------+
| NPU Name | Health | Power(W) Temp(C) Hugepages-Usage(page)|
| Chip | Bus-Id | AICore(%) Memory-Usage(MB) HBM-Usage(MB) |
+===========================+===============+====================================================+
| 0 910B2 | OK | 97.2 41 0 / 0 |
| 0 | 0000:C1:00.0 | 0 0 / 0 64231/ 65536 |
+===========================+===============+====================================================+
| 1 910B2 | OK | 93.3 43 0 / 0 |
| 0 | 0000:01:00.0 | 0 0 / 0 64231/ 65536 |
+===========================+===============+====================================================+
| 2 910B2 | OK | 93.5 39 0 / 0 |
| 0 | 0000:C2:00.0 | 0 0 / 0 64231/ 65536 |
+===========================+===============+====================================================+
| 3 910B2 | OK | 102.5 43 0 / 0 |
| 0 | 0000:02:00.0 | 0 0 / 0 64231/ 65536 |
+===========================+===============+====================================================+
| 4 910B2 | OK | 97.8 41 0 / 0 |
| 0 | 0000:81:00.0 | 0 0 / 0 3390 / 65536 |
+===========================+===============+====================================================+
| 5 910B2 | OK | 97.5 43 0 / 0 |
| 0 | 0000:41:00.0 | 0 0 / 0 3390 / 65536 |
+===========================+===============+====================================================+
| 6 910B2 | OK | 88.6 40 0 / 0 |
| 0 | 0000:82:00.0 | 0 0 / 0 3390 / 65536 |
+===========================+===============+====================================================+
| 7 910B2 | OK | 97.5 43 0 / 0 |
| 0 | 0000:42:00.0 | 0 0 / 0 3390 / 65536 |
+===========================+===============+====================================================+
+---------------------------+---------------+----------------------------------------------------+
| NPU Chip | Process id | Process name | Process memory(MB) |
+===========================+===============+====================================================+
| 0 0 | 1316011 | VLLMWorker_TP | 60891 |
+===========================+===============+====================================================+
| 1 0 | 1316012 | VLLMWorker_TP | 60891 |
+===========================+===============+====================================================+
| 2 0 | 1316013 | VLLMWorker_TP | 60891 |
+===========================+===============+====================================================+
| 3 0 | 1316014 | VLLMWorker_TP | 60891 |
+===========================+===============+====================================================+
| No running processes found in NPU 4 |
+===========================+===============+====================================================+
| No running processes found in NPU 5 |
+===========================+===============+====================================================+
| No running processes found in NPU 6 |
+===========================+===============+====================================================+
| No running processes found in NPU 7 |
+===========================+===============+====================================================+二、准备模型缓存
我不想让容器每次启动都重新下载模型,所以先在宿主机把模型缓存好。
我用的是 ModelScope:
pip install modelscope下载模型:
modelscope download --model Qwen/Qwen3.5-27B默认会下载到:
~/.cache/modelscope/hub/models/Qwen/Qwen3.5-27B如果你的磁盘空间比较紧张,也可以提前设置:
export MODELSCOPE_CACHE=/mnt/disk2/modelscope这样模型就会下载到你指定的目录。
三、docker-compose 配置
我最后用的是下面这份配置。
services:
vllm-ascend:
image: quay.io/ascend/vllm-ascend:v0.17.0rc1-openeuler
container_name: vllm-ascend
network_mode: host
shm_size: "1g"
restart: unless-stopped
environment:
VLLM_USE_MODELSCOPE: "true"
PYTORCH_NPU_ALLOC_CONF: "expandable_segments:True"
HCCL_BUFFSIZE: "512"
OMP_PROC_BIND: "false"
OMP_NUM_THREADS: "1"
TASK_QUEUE_ENABLE: "1"
devices:
- /dev/davinci0:/dev/davinci0
- /dev/davinci1:/dev/davinci1
- /dev/davinci_manager:/dev/davinci_manager
- /dev/devmm_svm:/dev/devmm_svm
- /dev/hisi_hdc:/dev/hisi_hdc
volumes:
- /mnt/disk2/modelscope/models:/root/.cache/modelscope/hub/models
- /usr/local/dcmi:/usr/local/dcmi
- /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool
- /usr/local/bin/npu-smi:/usr/local/bin/npu-smi
- /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/
- /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info
- /etc/ascend_install.info:/etc/ascend_install.info
command:
- vllm
- serve
- Qwen/Qwen3.5-27B
- --host
- 0.0.0.0
- --port
- "8000"
- --tensor-parallel-size
- "2"
- --served-model-name
- Qwen
- --max-model-len
- "133000"
- --max-num-batched-tokens
- "8096"
- --trust-remote-code
- --gpu-memory-utilization
- "0.95"
- --reasoning-parser
- qwen3
- --tool-call-parser
- qwen3_coder
- --enable-auto-tool-choice
- --async-scheduling
- --compilation-config
- '{"cudagraph_mode":"FULL_DECODE_ONLY"}'启动:
docker-compose up -d查看日志:
docker-compose logs -f如果看到:
INFO: Application startup complete.说明服务已经起来了。
四、这些参数到底是干什么的?
第一次看到这堆参数的时候,我的反应基本是:
这玩意儿每个都像是“先抄别人的,别问为什么”。
后来踩坑踩多了,终于知道它们各自负责什么。
1. VLLM_USE_MODELSCOPE=true
让 vLLM 不去 Hugging Face,而是优先从 ModelScope 找模型。
国内环境强烈建议开,不然根本无法下载模型。
2. tensor-parallel-size=2
表示两张卡一起跑。
比如 Qwen3.5-27B ,一张 910B 能跑但是上下文太小,两张卡正合适。
简单理解:
1:单卡
2:双卡
4:四卡
8:八卡
但不是越大越好。
我自己试过 8 卡,结果反而炸了:
aclnnCausalConv1d failed
blockDim is invalid最后发现不是显存不够,而是某些算子在 8 卡切分下有兼容性问题。
所以我的建议是:
先 1 卡验证
再 2 卡
稳了之后再考虑 4 卡
8 卡别一上来就冲
3. max-model-len=133000
这个是上下文长度。
也就是模型一次最多能吃多少 token。
133000 已经属于超长上下文了。当然这个模型原生支持 262,144 个 token,可扩展至最多 1,010,000 个 token。
它的好处很明显:
可以塞超长文档
可以做长聊天记录
PDF、会议纪要
但副作用也很明显:
占更多内存
并发会下降
首 token 会变慢
4. gpu-memory-utilization=0.95
虽然名字里写的是 GPU,但在 Ascend 上它其实表示“最多吃掉多少设备内存”。
0.95 = 吃掉 95%这个值越大,模型越容易跑下更长上下文、更高并发。
但也越容易翻车。
我的经验:
0.90:稳
0.95:性能更好
0.98:准备随时爆炸
如果你经常碰到:
CUDA out of memory
NPU out of memory先别急着怀疑模型,先把它降到:
0.905. PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
这个参数我一开始完全没看懂。
后来才知道,它是为了减少内存碎片。
有时候明明设备还有内存,但模型就是报 OOM。
原因可能不是“没内存”,而是“剩下的内存被切得太碎了”。
这个参数会让内存分配更灵活,对长上下文、多并发特别有帮助。
建议直接开。
6. --reasoning-parser qwen3
这是给 Qwen3 系列准备的“推理格式解析器”。
不开的话,模型虽然也能输出,但有些 reasoning 字段、思考内容、结构化返回可能会不正常。
如果你部署的是 Qwen3.5,直接写:
--reasoning-parser qwen37. --tool-call-parser qwen3_coder
这是工具调用解析器。
如果你希望模型支持:
function calling
tool calling
自动调用天气、搜索、数据库、浏览器
那它就很重要。
再配合:
--enable-auto-tool-choice模型就能自动决定:
“我应该去调用哪个工具,而不是直接瞎编。”
五、测试一下接口
服务起来以后,可以直接用 curl 测。
最简单的聊天:
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen",
"messages": [
{
"role": "user",
"content": "你好,介绍一下你自己"
}
]
}'六、测试视觉能力
Qwen3.5 是统一多模态模型,原生支持视觉(图片、视频输入)。
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "图里有什么?"
},
{
"type": "image_url",
"image_url": {
"url": "https://your-image-url"
}
}
]
}
]
}'七、测试工具调用
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen",
"messages": [
{
"role": "user",
"content": "帮我查一下北京今天的天气"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取天气",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string"
}
},
"required": ["city"]
}
}
}
],
"tool_choice": "auto"
}'如果返回里出现:
"tool_calls": [
{
"function": {
"name": "get_weather",
"arguments": "{\"city\":\"北京\"}"
}
}
]说明工具调用能力已经正常了。
八、我踩过的几个坑
1. 镜像不对
910B2 和 910B3 对应的镜像可能不一样。
镜像不匹配时,最常见的症状是:
worker 一直起不来
设备识别失败
推理一执行就崩2. compilation-config JSON 写错
这个参数必须是真正的 JSON。
错误:
cudagraph_mode:FULL_DECODE_ONLY正确:
{"cudagraph_mode":"FULL_DECODE_ONLY"}否则 vLLM 会直接启动失败。
3. 视觉模型必须关掉 Flash Comm V1
如果你部署的是 VL 模型(Qwen3.5 原生就是 VL 模型),可能会看到:
Flash Comm V1 is not supported for VL models这时候加上:
environment:
VLLM_ASCEND_ENABLE_FLASHCOMM1: "0"