
很多人在使用大模型 API 或部署 vLLM、SGLang 这类推理服务时,都会看到一个词:缓存命中。
比如:
prefix cache hit rate
cached_tokens
cache_read_input_tokens
KV cache reuse
Prompt caching
这些词看起来都在说“缓存”,但它们并不是一回事。更容易误解的是,很多人会以为:
大模型缓存命中 = 上一次回答过的问题,这次直接把答案拿出来。
这其实只说对了一小部分。
在大模型推理系统里,最核心、最常见、也最值得优化的缓存,并不是“缓存最终答案”,而是:
缓存模型处理 Prompt 后产生的中间计算状态,也就是 KV Cache。
换句话说,Prompt 是输入,KV Cache 是模型读完输入后留下的内部状态,Prefix Cache / Prompt Cache 则是把这份状态复用起来。
一、先把几个概念分清楚
在大模型系统里,至少有四种容易混在一起的“缓存”:
本文重点讲前三个,尤其是 Prompt、KV Cache、Prefix Cache 的关系。
二、Prompt 是什么?
Prompt 就是你发给模型的输入内容。
它可能包括:
系统提示词
用户问题
历史对话
工具定义
RAG 检索出来的文档
输出格式要求
示例 few-shot
例如:
你是一个 Java 架构师。
请用通俗语言解释 Spring Boot 的自动配置机制。
这段文字会先被 tokenizer 切成 token,然后进入模型计算。
可以简单理解为:
Prompt = 模型要阅读的原始材料
它是外部可见的,人能读懂,也能被业务系统拼接、修改、记录。
三、KV Cache 是什么?
KV Cache 是模型内部的计算缓存。
Transformer 模型在生成文本时,需要通过 attention 回看前面已经出现过的 token。
如果每生成一个新 token,都把前面所有 token 重新算一遍,成本会非常高。
所以模型会把之前 token 在每一层 attention 里计算出来的 Key / Value 保存下来。
下一次生成新 token 时,就可以直接复用这些 Key / Value,而不用重新计算历史 token。
可以简单理解为:
KV Cache = 模型读完 Prompt 后形成的“内部记忆状态”
它不是文本,也不是答案,而是一堆高维张量。
四、一次大模型请求是怎么跑的?
下面这张图可以把 Prompt 和 KV Cache 的关系画清楚。
一次请求大致分成两个阶段:
第一阶段叫 Prefill。
模型会把输入 Prompt 全部处理一遍,并生成对应的 KV Cache。
第二阶段叫 Decode。
模型开始一个 token 一个 token 地生成答案,并持续复用前面已经生成的 KV Cache。
所以,如果 Prompt 很长,Prefill 就会很重。
比如你每次请求都带上 2 万 token 的文档,那么模型每次都要先“读完这 2 万 token”,才能开始回答。
这就是缓存优化的入口。
五、缓存命中到底命中了什么?
在 Prefix Cache 或 Prompt Caching 场景里,命中的通常不是最终回答,而是:
相同 Prompt 前缀对应的 KV Cache
假设第一次请求是:
[系统提示词][工具定义][长文档][用户问题 A]
第二次请求是:
[系统提示词][工具定义][长文档][用户问题 B]
这两次请求前面的大段内容完全一样,只有最后的问题不同。
那么第一次请求处理完:
[系统提示词][工具定义][长文档]
之后,推理引擎可以把这一段前缀对应的 KV Cache 保存下来。
第二次请求进来时,就不用重新计算这段内容了,只需要从用户问题 B 开始继续计算。
vLLM 的 Automatic Prefix Caching 就是这个思路:它会缓存已有请求的 KV Cache,如果新请求和已有请求共享相同前缀,就可以复用共享部分,跳过这部分重复计算。(vLLM)
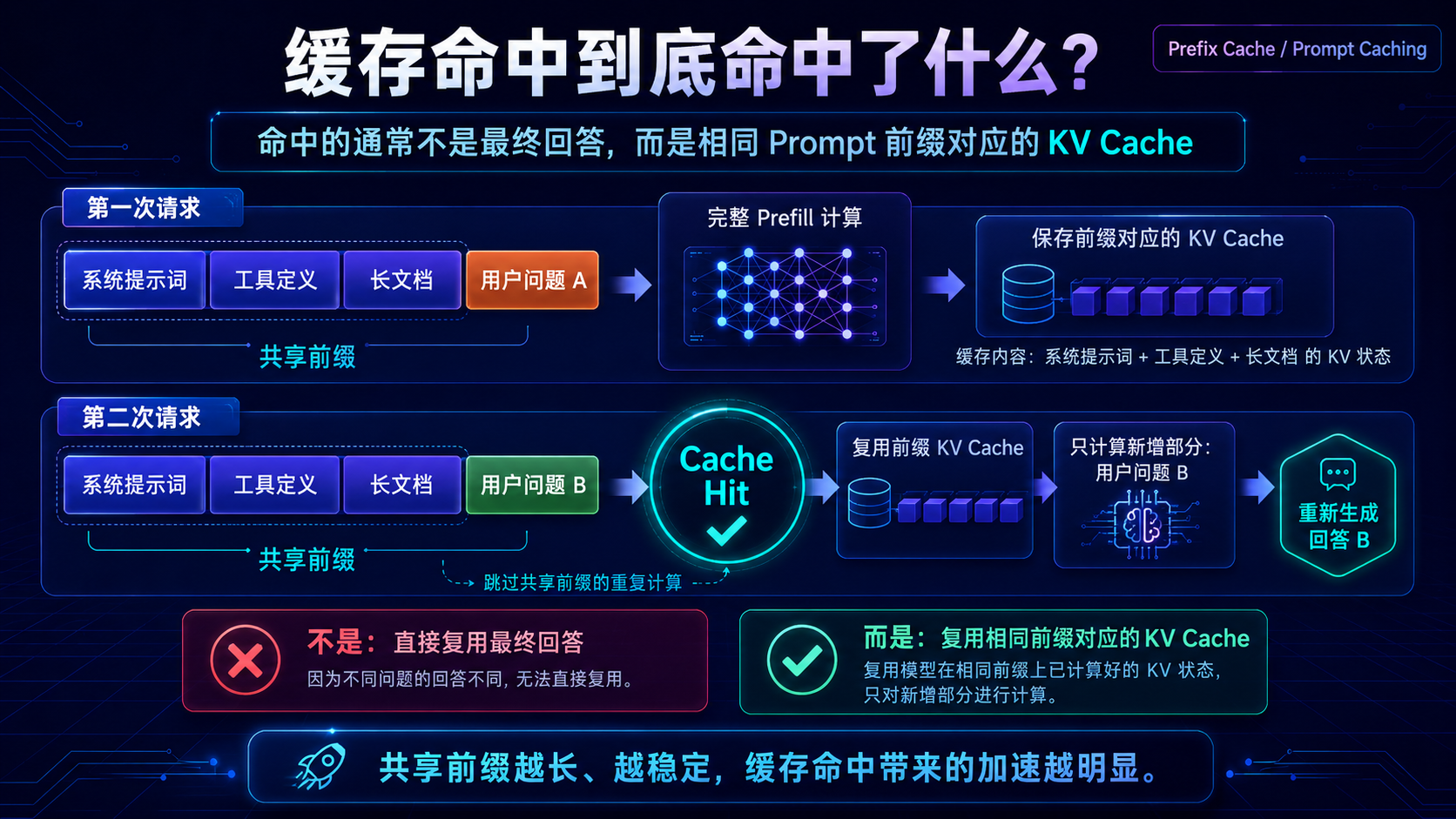
六、用图看 Prefix Cache 命中
这个过程里,模型并没有偷懒返回旧答案。
它只是不用重新读一遍相同的系统提示词、工具定义和长文档。
最终回答仍然是针对“用户问题 B”重新生成的。
所以 Prefix Cache 更像是:
不用重新读同一本书,直接恢复到“已经读完这本书”的状态。
七、为什么必须是“前缀”一致?
缓存命中最关键的条件是:
相同内容必须出现在 Prompt 的开头,并且 token 级别保持一致。
OpenAI 的 Prompt Caching 文档也明确说明,缓存命中只可能发生在 exact prefix match,因此应该把静态内容放在 prompt 开头,把用户变量、时间、临时信息等动态内容放在末尾。(OpenAI 开发者)
这就解释了一个常见问题:
很多人以为自己每次请求都带了相同的系统提示词和文档,应该可以命中缓存。
但实际上,因为他在最前面加了时间戳:
当前时间:2026-05-23 10:01:22
[系统提示词]
[工具定义]
[长文档]
[用户问题]
下一次请求变成:
当前时间:2026-05-23 10:01:28
[系统提示词]
[工具定义]
[长文档]
[用户问题]
虽然只有时间变了,但它出现在最前面。
于是整个前缀从一开始就不一致,后面再长的系统提示词和文档也很难复用。
八、错误的 Prompt 结构
这种结构非常不利于缓存命中。
因为最前面的内容每次都变:
当前时间变了
request_id 变了
用户状态变了
临时参数变了
只要前面变了,后面的长文档即使完全一样,也无法形成稳定的公共前缀。
九、正确的 Prompt 结构
更推荐这样组织:
也就是:
先放稳定内容
再放半稳定内容
最后放动态内容
推荐模板:
[系统提示词]
[工具定义]
[输出格式要求]
[固定背景知识]
[长文档内容]
[历史对话]
[本次用户问题]
[当前时间、用户变量、临时参数]
这样设计的好处是:
只要前面的大段内容不变,后续请求就更容易命中 Prefix Cache。
十、KV Cache 和 Prompt 的本质区别
可以用一张表总结:
一句话总结:
Prompt 是给模型看的内容;
KV Cache 是模型看完内容后留下的内部计算状态。
十一、Prompt Cache 名字容易误导
“Prompt Cache”这个名字有点容易误导。
很多人看到 Prompt Cache,会以为缓存的是 Prompt 文本。
但从推理优化角度看,真正有价值的不是保存那段文本,而是保存这段文本经过模型计算后的中间状态。
所以更准确地说:
Prompt Cache = 缓存某段 Prompt 对应的 KV Cache 或上下文处理结果
不同厂商的实现细节不完全一样,但用户看到的效果类似:
相同长前缀再次出现时,延迟降低,输入成本降低。
OpenAI 的 API 响应里可以通过 usage.prompt_tokens_details.cached_tokens 看到命中的 cached tokens;OpenAI 文档也说明,Prompt Caching 对较长 prompt 自动生效,并依赖重复的前缀匹配。(OpenAI 开发者)
Claude 也提供类似的统计字段,比如 cache_creation_input_tokens 和 cache_read_input_tokens,用来区分本次写入缓存的 token 和从缓存读取的 token。(Claude API Docs)
Gemini 则区分 implicit caching 和 explicit caching;explicit caching 可以把一段内容先缓存起来,后续请求引用这份缓存内容。(Google AI for Developers)
十二、它和“缓存最终回答”有什么区别?
这点非常关键。
Prefix Cache / KV Cache 复用的是:
模型读完前缀后的状态
Semantic Cache / Result Cache 复用的是:
上一次生成过的最终答案
二者风险完全不同。
如果你做的是文档问答、Agent、代码助手、长上下文对话,优先应该关注 Prefix Cache。
如果你做的是客服 FAQ、固定知识问答、重复查询,才适合考虑 Semantic Cache。
十三、为什么缓存命中能降低首 token 延迟?
大模型回答慢,通常分两类慢:
第一类是 读题慢。
也就是 Prompt 很长,模型要先处理大量输入 token。
第二类是 写答案慢。
也就是输出 token 很多,模型要一个一个生成。
Prefix Cache 主要优化第一类:读题慢。
所以缓存命中最明显改善的是:
TTFT:Time To First Token,首 token 延迟
如果你的应用里,用户每次输入都很短,输出却很长,那么 Prefix Cache 的收益可能没那么明显。
但如果你的应用每次都带很长的系统提示词、工具定义、文档上下文,缓存收益会非常明显。
十四、vLLM 里怎么开启 Prefix Cache?
如果你用 vLLM,可以通过参数开启 Automatic Prefix Caching:
vllm serve /path/to/model \
--host 0.0.0.0 \
--port 8000 \
--enable-prefix-caching
vLLM 官方文档中,Automatic Prefix Caching 的定义就是:缓存已有请求的 KV Cache,当新请求共享相同前缀时,直接复用这部分 KV Cache,从而跳过共享部分的计算。(vLLM)
对于你这种经常部署 vLLM 的场景,最应该关注的不是“有没有打开参数”,而是:
Prompt 拼接顺序是否稳定
系统提示词是否频繁变化
工具 schema 是否每次都重新排序
RAG 文档是否放在了合适位置
多副本部署时请求是否打到了同一个缓存池
只开参数,不改 Prompt 结构,命中率可能依然很低。
十五、一个典型反例:工具定义每次顺序都变
很多 Agent 系统会在请求里带 tools:
[
{ "name": "search" },
{ "name": "read_file" },
{ "name": "write_file" }
]
如果下一次变成:
[
{ "name": "read_file" },
{ "name": "search" },
{ "name": "write_file" }
]
语义上看,工具还是这几个。
但从 token 序列看,前缀已经变了。
这会直接影响缓存命中。
所以工程上要注意:
工具列表顺序固定
JSON 字段顺序固定
不要动态生成无意义字段
不要把时间戳、随机 ID 放在前面
十六、缓存命中率怎么理解?
不同平台的统计口径不完全一样,但一般可以从两个角度看。
第一种是 token 维度:
缓存命中率 = 命中的 prompt tokens / 总 prompt tokens
例如:
{
"prompt_tokens": 20000,
"cached_tokens": 18000
}
大概可以理解为:
这次输入里,有 18000 tokens 复用了缓存
第二种是 block 维度。
像 vLLM 这类推理引擎通常会把 KV Cache 分块管理。
Prefix Cache 命中时,并不是一个字符一个字符匹配,而是按 token block 或缓存块来复用。
所以你看到的指标可能叫:
prefix cache hit rate
kv cache hit rate
cache read tokens
cached tokens
这些指标都在描述同一个核心问题:
这次请求有多少输入计算被复用了?
十七、什么时候收益最大?
Prefix Cache 最适合这些场景:
长系统提示词
长工具定义
固定 few-shot 示例
长文档问答
代码仓库问答
多轮 Agent 调用
同一知识库被多人反复提问
同一个任务模板被大量用户复用
比如:
[固定 Agent 角色设定 3000 tokens]
[固定工具定义 5000 tokens]
[项目代码上下文 30000 tokens]
[用户问题 100 tokens]
如果前面 38000 tokens 可以复用,后续请求的 prefill 成本会明显下降。
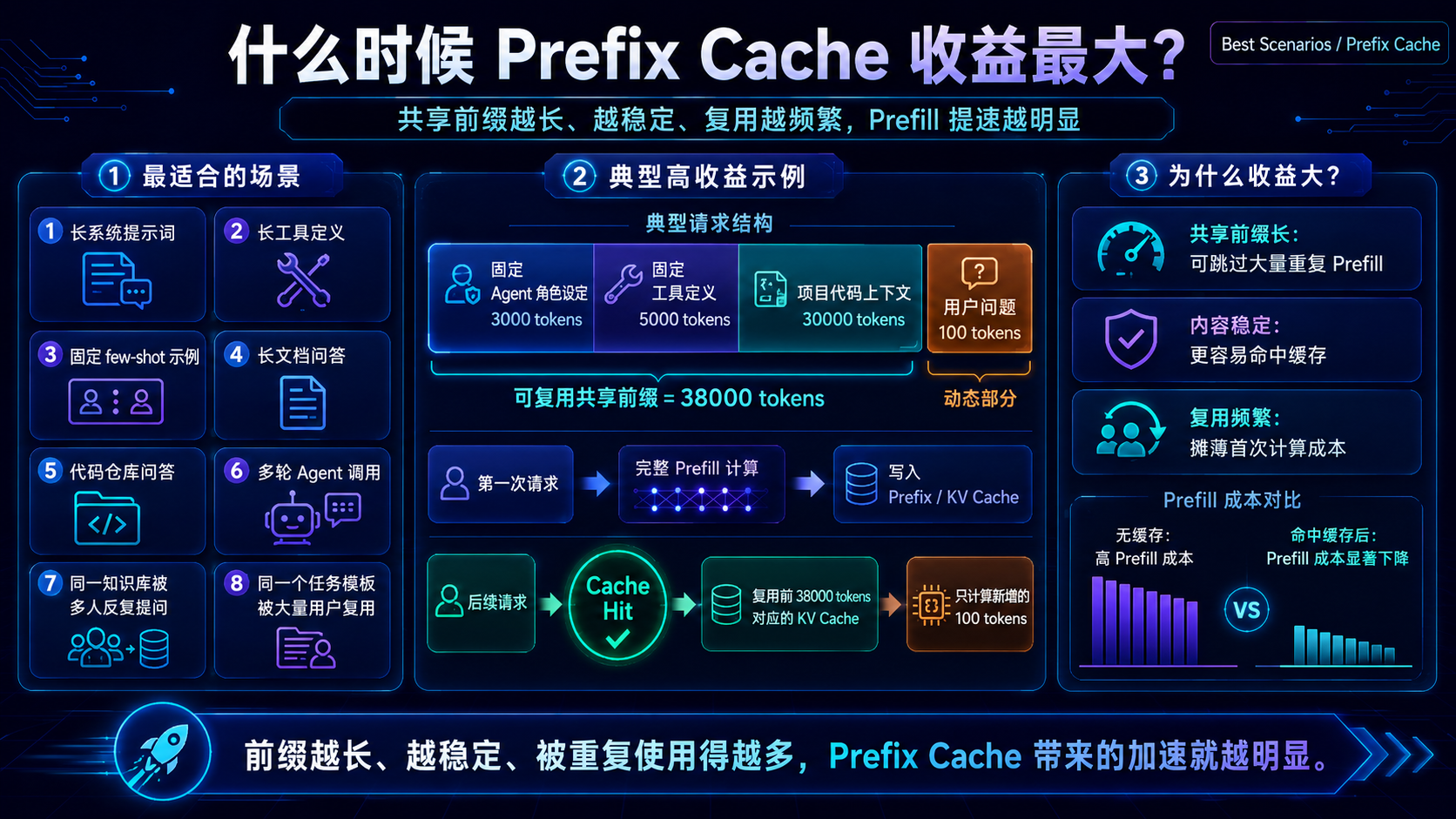
十八、什么时候收益不明显?
下面这些场景,Prefix Cache 收益就有限:
每次 Prompt 都完全不同
动态内容放在 Prompt 最前面
RAG 每次检索出来的文档都不同,而且排在前面
Prompt 很短
输出特别长,瓶颈在 Decode 阶段
多实例部署但没有粘滞路由
缓存容量太小,刚写入就被淘汰
尤其是 RAG 系统很容易踩坑。
很多 RAG 模板是:
[本次检索结果]
[系统提示词]
[用户问题]
如果检索结果每次都不一样,那整个前缀每次都变。
更好的做法通常是:
[固定系统提示词]
[固定回答规范]
[固定工具说明]
[稳定背景知识]
[本次检索结果]
[用户问题]
这样至少前面的系统提示词、回答规范、工具说明可以稳定命中。
十九、不要把缓存命中神化
缓存命中不是万能优化。
它解决的是:
重复 Prompt 前缀导致的重复 prefill 计算
它不解决:
模型本身太大
输出 token 太多
batch 调度不合理
显存不足
并发过高
网络传输慢
后处理慢
也就是说,如果你的接口慢是因为模型输出 3000 tokens,那么 Prefix Cache 只能帮你更快开始输出,不能让模型瞬间生成完整答案。
二十、工程实践 checklist
如果你想提高大模型缓存命中率,可以按这个清单检查:
1. 固定系统提示词是否放在最前面?
2. 工具定义是否固定顺序?
3. JSON 字段序列化是否稳定?
4. few-shot 示例是否稳定?
5. 长文档是否尽量稳定?
6. 用户问题、时间戳、request_id 是否放在末尾?
7. 是否避免在前缀里加入随机数?
8. RAG 结果是否不要放在最开头?
9. 多副本部署是否考虑缓存亲和性?
10. 是否监控 cached_tokens / cache_read_tokens / prefix cache hit rate?
核心原则只有一句:
越稳定的内容,越往前放;
越动态的内容,越往后放。
二十一、最终总结
大模型里的缓存命中,最关键的不是“缓存答案”,而是“缓存模型已经读过的上下文状态”。
可以用三句话总结:
Prompt 是输入内容。
KV Cache 是模型处理输入后产生的内部计算状态。
Prompt Cache / Prefix Cache 是把相同前缀对应的 KV Cache 复用起来。
如果用一个生活化类比:
Prompt = 给模型看的书
KV Cache = 模型读完书后形成的临时记忆
Prefix Cache = 下次看到同一本书的前半部分时,不用重新读,直接恢复读完后的状态
Semantic Cache = 看到相似问题时,直接拿以前的答案来用
所以,做大模型应用时,不要只问:
有没有开启缓存?
更应该问:
我的 Prompt 结构适合缓存命中吗?
我的固定内容是不是放在了最前面?
我的动态内容是不是破坏了公共前缀?
我监控到的 cached tokens 到底有多少?
真正的优化,不是加一个缓存开关,而是从 Prompt 结构、请求路由、上下文组织方式上,让模型推理系统更容易复用已经算过的内容。