
如果只看参数规模,DeepSeek-V4 很容易被理解成又一次“大模型继续变大”的发布:DeepSeek-V4-Pro 拥有 1.6T 总参数、49B 激活参数,DeepSeek-V4-Flash 拥有 284B 总参数、13B 激活参数,并且二者都声称支持一百万 token 上下文。但通读论文后会发现,DeepSeek-V4 真正想强调的并不是单纯堆参数,而是围绕“百万 token 上下文能否常态化使用”这件事,对模型架构、训练优化、推理系统和后训练流程做了一整套效率重构。
这也是这篇论文最值得技术读者关注的地方。过去两年,长上下文能力已经成为大模型竞争中的显性指标,但“能放进窗口”和“能以可接受成本持续使用”之间仍然有很大距离。上下文越长,注意力计算、KV cache、显存占用、推理延迟和系统调度都会被放大;如果再叠加推理模型常见的 test-time scaling,模型在回答前生成更长的思考链,成本问题会进一步加重。DeepSeek-V4 的主线,正是试图把长上下文从展示型能力推进到工程上更可用的能力。
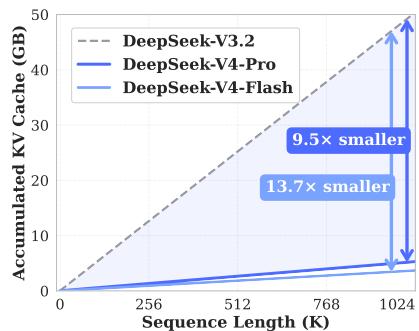
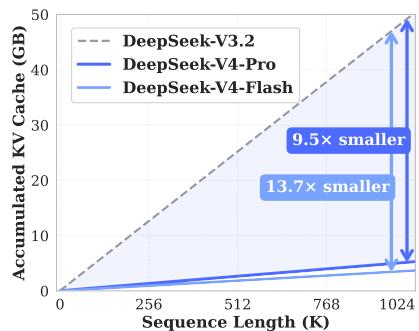
按照论文说法,DeepSeek-V4 系列在一百万 token 上下文场景下,相比 DeepSeek-V3.2 显著降低了单 token 推理 FLOPs 和 KV cache。DeepSeek-V4-Pro 在 1M token 上下文下只需要 DeepSeek-V3.2 约 27% 的单 token 推理 FLOPs 和 10% 的 KV cache;更小的 DeepSeek-V4-Flash 则进一步降到约 10% 的单 token FLOPs 和 7% 的 KV cache。这里的数字很重要,因为它说明论文并不只是追求“窗口长度更大”,而是在回答一个更实际的问题:当上下文真的来到百万级时,模型还能不能以较低边际成本继续读、继续推理、继续作为 agent 工作。
本文基于论文DeepSeek_V4 论文做技术解读。需要提前说明的是,论文中的一部分评测来自 DeepSeek 内部框架或内部任务集,且 DeepSeek-V4 被描述为 preview version。因此,下文会尽量区分“论文报告的结果”和“从技术设计可以推导出的趋势”,避免把论文中的内部结论直接等同于独立第三方验证。
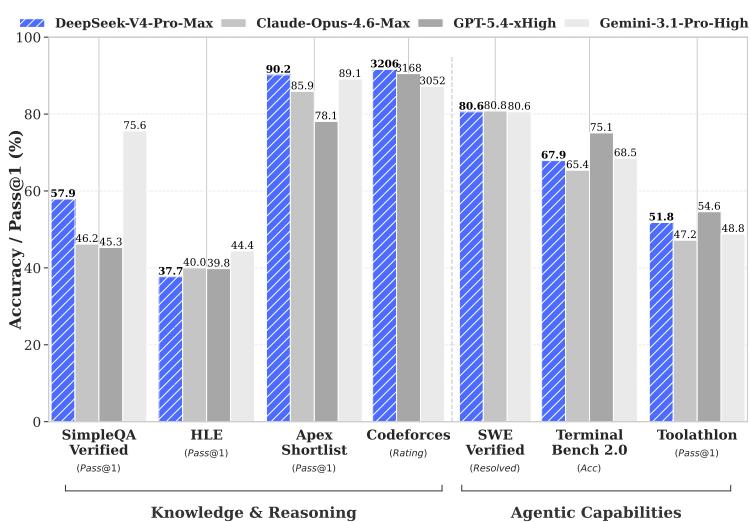
DeepSeek-V4-Pro-Max benchmark 表现与 V4 系列长上下文效率对比:
效率对比补充图:
KV cache 与 FLOPs 对比补充图:
一、DeepSeek-V4 要解决的核心问题:长上下文的效率墙
长上下文不是一个单点能力,而是一组互相牵连的系统问题。标准 Transformer 注意力在序列长度上存在高复杂度问题,序列越长,注意力计算越昂贵;同时,为了在自回归生成中复用历史信息,模型需要保存 KV cache,上下文越长,cache 规模越大,显存和内存压力越明显。对于短上下文任务,这些成本可能还可以被硬件和批处理策略掩盖;但当上下文长度扩展到百万 token,原有设计的成本会变成主瓶颈。
更关键的是,推理模型的发展让这个瓶颈更突出。所谓 test-time scaling,本质上是让模型在推理阶段投入更多计算,例如更长的思考、更复杂的自检、更充分的工具调用或多轮搜索。它带来的能力提升已经被许多 reasoning model 证明,但它也天然依赖更长的上下文和更高的推理预算。模型既要读大量外部材料,又要保留中间推理轨迹,还要在多轮工具调用中持续维护状态;如果长上下文成本没有被压下来,test-time scaling 的上限就会被系统成本提前卡住。
DeepSeek-V4 的论文把这个问题放在了非常中心的位置。它没有把百万 token 上下文仅仅描述成一个产品规格,而是把它视作下一阶段大模型能力扩展的基础设施:复杂 agent 工作流、大规模跨文档分析、长周期任务、甚至未来的在线学习,都依赖模型高效处理超长序列。换句话说,百万 token 的意义不只是“能塞进一本书或一堆文档”,而是让模型在更长时间尺度和更复杂任务链条中保持上下文连续性。
因此,DeepSeek-V4 的技术路线可以概括为一句话:用架构压低长上下文边际成本,用训练和后训练补足能力,用系统工程把这套设计落到可运行的训练与推理框架中。Pro 和 Flash 的差异,则是在这条路线上的两个不同取舍:Pro 更强调能力上限,Flash 更强调效率和性价比。
二、Pro 与 Flash:不是一个模型的大小杯,而是两种成本曲线
论文中 DeepSeek-V4 系列包括两个主要模型:DeepSeek-V4-Pro 和 DeepSeek-V4-Flash。二者都采用 MoE 架构,都支持一百万 token 上下文,但参数规模和激活规模差异明显。V4-Pro 的总参数为 1.6T,每次前向激活 49B;V4-Flash 的总参数为 284B,每次前向激活 13B。这个设计延续了 MoE 的基本思路:用较大的总参数容量承载知识和能力,同时在单次推理中只激活部分专家,以控制计算成本。
从论文给出的定位看,V4-Pro 是更偏能力上限的版本,尤其在 Pro-Max 这一最大 reasoning effort 模式下,论文称其在开放模型中刷新了多项表现。V4-Flash 则更像效率优先版本:总参数和激活参数都更小,但在许多评测中仍然表现强劲。论文在预训练基座模型对比中提到,V4-Flash-Base 尽管参数预算更紧,却在多个任务上超过 DeepSeek-V3.2-Base;V4-Pro-Base 则进一步在知识、推理、代码和长上下文等方向取得更高分数。
这类结果最值得关注的不是单个 benchmark 的胜负,而是架构效率是否真的改变了能力与成本之间的关系。按照论文表述,V4-Flash 在 1M token 上下文下相对 V3.2 只需要约 10% 的单 token FLOPs 和 7% 的 KV cache。如果这个成本曲线能够在实际部署中成立,那么 Flash 的价值就不仅是“便宜版本”,而是让长上下文 agent、批量文档分析、持续对话等场景具备更好的经济性。
当然,MoE 模型的“总参数”和“激活参数”也需要谨慎理解。总参数代表模型容量,但不等同于单次推理计算量;激活参数更接近每个 token 实际走过的计算规模,但真实延迟还取决于专家路由、通信、kernel 效率、cache 管理和硬件支持。DeepSeek-V4 论文之所以花大量篇幅讲基础设施,正是因为 MoE 的理论效率并不会自动转化为端到端效率。对于一个真正要服务百万 token 的模型,架构、kernel、通信、存储和调度必须一起优化。
三、混合注意力:CSA 与 HCA 如何压低百万上下文成本
图 2,DeepSeek-V4 系列整体架构
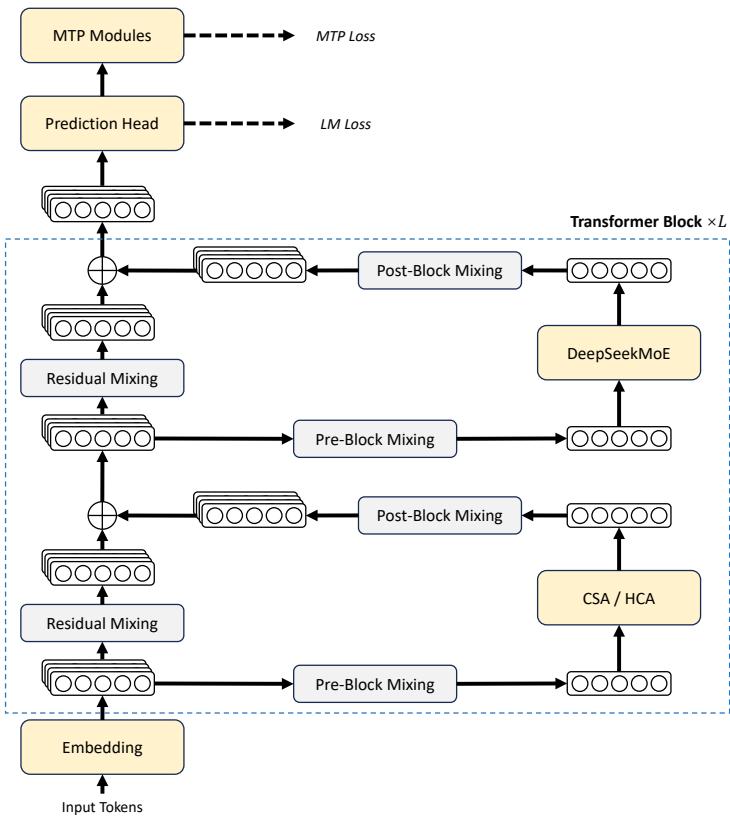
论文中强调,注意力层采用 CSA/HCA 混合机制,前馈层采用 DeepSeekMoE,并用 mHC 强化传统残差连接。
DeepSeek-V4 最核心的架构变化,是引入混合注意力机制,将 Compressed Sparse Attention(CSA)和 Heavily Compressed Attention(HCA)结合起来。可以粗略理解为:CSA 试图在保留较强检索和选择能力的同时压缩 KV;HCA 则进一步做重压缩,用更低成本保留长距离信息。二者共同服务于一个目标:不要让每个新 token 都以近似全量的代价回看百万级历史。
图 3:CSA 核心结构。论文描述中,CSA 会先压缩 KV 条目数量,再结合稀疏注意力机制进一步加速。
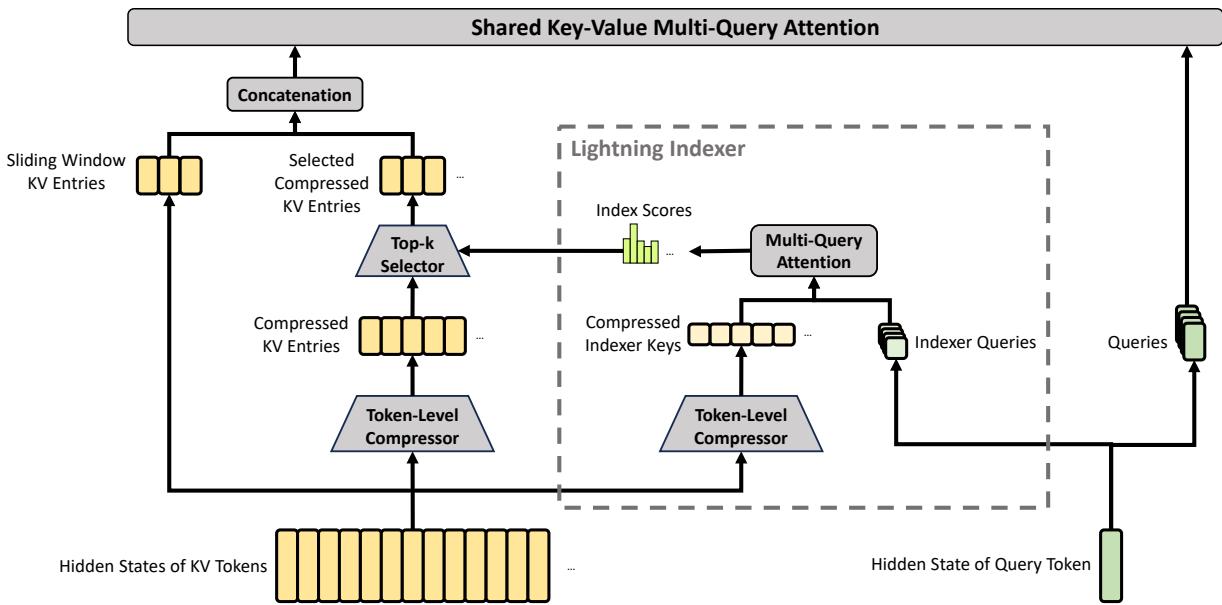
图 4:HCA 核心结构。HCA 采用更重的 KV 压缩,把更多 token 的 KV 信息合并到更少条目中,用于降低超长上下文下的持续访问成本。
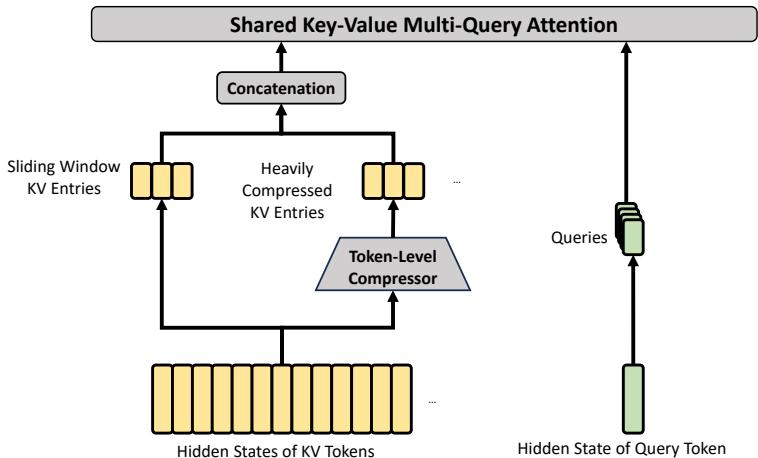
CSA 的思路是先沿序列维度压缩 KV cache,再在压缩后的表示上做稀疏注意力。与直接对原始长序列做注意力相比,这样可以减少 KV 条目数量;与简单截断或粗暴摘要相比,它仍然保留了面向注意力机制的可检索结构。论文还将 CSA 与 DeepSeek Sparse Attention 联系起来,说明它并不是单纯“把上下文变短”,而是在压缩之后继续用稀疏选择机制寻找相关信息。
HCA 的压缩更激进。论文描述中,HCA 会把更多 token 的 KV 合并成一个更高度压缩的表示,同时保持 dense attention。这个设计背后有一个现实判断:长上下文中的信息并非全部同等重要,也不是所有历史位置都需要以原始粒度保留。对于很远的历史内容,模型可能更需要一种低成本的全局记忆;对于近期或关键位置,则需要更精细的访问能力。CSA 与 HCA 的混合,正是在不同信息粒度之间做分工。
这种分工也解释了为什么 DeepSeek-V4 没有只采用一种注意力替代方案。纯稀疏注意力可能会漏掉一些需要全局聚合的信息;纯重压缩又可能损失细节。混合方案的目标,是让模型既能在百万级上下文中保持可扩展性,又不完全牺牲对关键细节的定位能力。论文在长上下文评测中报告了 MRCR 等任务表现,意在说明这种设计不仅降低成本,也能保留长上下文理解能力。
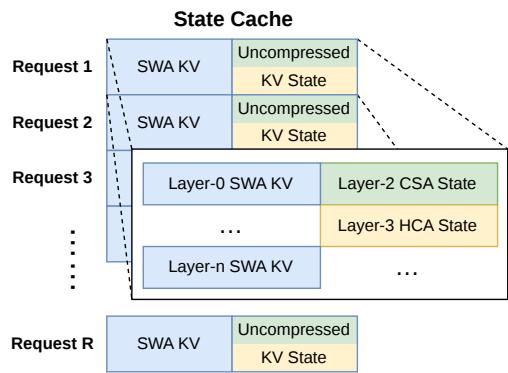
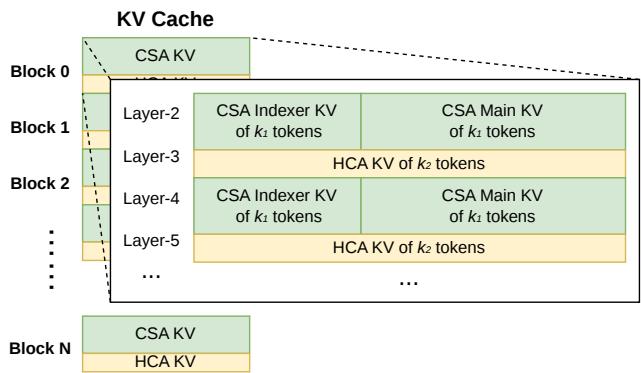
从工程角度看,混合注意力的难点并不只在算法本身,还在 KV cache 的组织方式。不同注意力层、不同压缩状态、不同历史片段会对应不同 cache 结构。如果 cache 管理跟不上,理论上的 FLOPs 降低可能会被内存访问、碎片化和调度开销抵消。DeepSeek-V4 因此在推理框架中设计了异构 KV cache:既有 CSA/HCA 的经典 KV cache,也有 SWA 和尚未压缩 token 的 state cache,并进一步引入 on-disk KV cache 来支持共享前缀复用。
这部分设计对长上下文应用尤其重要。许多真实任务并不是每次都从零开始读一百万 token,而是大量请求共享同一批长文档、代码库、知识库或历史材料。如果共享前缀的 KV cache 可以被高效复用,甚至在磁盘层面保存和管理,长上下文的摊销成本会明显下降。这也是 DeepSeek-V4 把“百万 token”从模型规格延伸到推理系统的原因。
四、mHC:为什么残差连接也需要升级
除了注意力,DeepSeek-V4 还引入了 Manifold-Constrained Hyper-Connections(mHC)来增强传统残差连接。残差连接在 Transformer 中通常被视为基础结构,但当模型变得更深、更宽、更复杂,尤其叠加 MoE、长上下文和更激进的训练策略时,信号传播稳定性会变得更加关键。mHC 试图给残差路径增加一个新的可扩展维度,同时用约束避免训练不稳定。
论文先介绍了标准 Hyper-Connections 的思路:把残差流的宽度扩展为多个分支,通过输入映射、残差变换和输出映射来更新状态。这样做的好处是,内层 Transformer block 的 hidden size 不必同步扩大,但残差流可以拥有更丰富的组合方式。换句话说,它给模型增加了一种不同于扩大 hidden size 或增加层数的扩展轴。
问题在于,标准 HC 在多层堆叠时可能出现数值不稳定。DeepSeek-V4 采用的 mHC 核心做法,是把残差映射矩阵约束到双随机矩阵所在的流形,也就是论文中提到的 Birkhoff polytope。这个约束可以让残差变换具有非扩张性质,降低前向传播和反向传播中信号被放大的风险。论文还提到,相关输入和输出变换也会通过非负和有界约束来降低信号抵消风险。
用更直观的话说,mHC 不是让残差路径自由地“想怎么混就怎么混”,而是在一个稳定的几何约束内进行混合。这样做的意义在于:模型仍然可以获得更丰富的残差信息流,但训练时更不容易因为矩阵放大、信号抵消或深层叠加而失控。对于 1.6T 总参数、49B 激活参数的 V4-Pro 来说,这类稳定性设计不是锦上添花,而是大规模训练能否顺利推进的基础条件之一。
值得注意的是,mHC 本身也会带来实现成本。论文在训练框架中专门讨论了 mHC 的低成本实现,包括重计算和 fused kernel。这说明 DeepSeek-V4 的设计并不是“先加复杂结构,再让系统硬扛”,而是同时考虑结构收益与实现开销。对于今天的大模型训练而言,一个结构如果不能被高效实现,很难在万亿参数级别真正落地。
五、Muon 与 FP4:训练效率和数值稳定性的另一条线
DeepSeek-V4 还引入 Muon 优化器。论文对 Muon 的定位是带来更快收敛和更好的训练稳定性。优化器看似没有注意力机制那么显眼,但在超大规模训练中,优化器的影响非常实际:它决定同样数据和算力下模型能否更快达到目标能力,也影响训练过程中是否容易发生不稳定。
论文将 DeepSeek-V4-Pro 和 V4-Flash 分别训练在 33T 和 32T tokens 上。这个规模下,任何收敛效率的改善都会转化为巨大的算力影响。Muon 的引入可以看作 DeepSeek-V4 对“效率”的另一层理解:不仅推理要省,训练也要尽量高效;不仅要降低 FLOPs,还要减少不稳定带来的回滚、调参和训练风险。
与此同时,DeepSeek-V4 使用了 FP4 quantization-aware training,尤其针对 MoE expert weights 和 indexer QK path 等部分。论文提到,DeepSeek-V4 系列的 routed expert parameters 使用 FP4 精度。FP4 的价值首先是降低存储和带宽压力,其次是在未来硬件支持更成熟时,有机会进一步转化为计算效率收益。论文也比较谨慎地指出,在现有硬件上 FP4×FP8 操作的峰值 FLOPs 与 FP8×FP8 目前相同,但未来硬件理论上可以让相关操作更高效。
这段表述值得保留其谨慎性。FP4 并不是魔法,它依赖训练策略、量化感知、kernel 支持和硬件路径。如果量化误差控制不好,模型能力会受损;如果硬件不能充分利用低精度,理论节省也无法完全兑现。DeepSeek-V4 的论文把 FP4 放进训练和后训练基础设施里,而不是只作为推理压缩手段,这说明它试图从训练阶段就让模型适应低精度约束。
六、基础设施:大模型能力越来越像系统工程
DeepSeek-V4 论文有相当篇幅讨论 general infrastructures,这一点非常关键。对于 MoE 和百万 token 上下文模型,端到端效率经常不取决于某一个公式,而取决于系统中最慢、最不稳定、最难复用的环节。
首先是 MoE 专家并行中的通信与计算重叠。MoE 的优势在于稀疏激活,但代价是 token 需要被路由到不同专家,带来 dispatch、combine 和跨设备通信。论文提出更细粒度的通信-计算重叠,并实现单个 fused kernel 来覆盖 MoE 模块中的计算、通信和内存访问。这里的目标是减少通信等待,让专家计算和数据移动尽可能并行发生。
其次是 TileLang。论文将 TileLang 描述为一种 DSL,用于在开发效率和运行效率之间取得平衡。大模型系统中大量性能瓶颈都落在 kernel 层,但手写高性能 CUDA kernel 成本极高,也不利于快速迭代。DSL 的意义在于让团队更快开发和维护高性能 kernel,尤其当注意力、MoE、量化和 cache 结构不断变化时,kernel 开发效率会直接影响模型迭代速度。
第三是 batch-invariant 和 deterministic kernel libraries。确定性在大规模训练和推理中经常被低估。模型训练出现异常时,如果 kernel 行为不能稳定复现,定位问题会非常困难;推理服务中,如果 batch 组成变化导致输出差异,也会增加调试和验证成本。论文强调 bitwise reproducibility,说明 DeepSeek-V4 不只是追求跑得快,也在追求可复现、可调试、可验证。
第四是训练框架中的长上下文并行与自动微分扩展。百万 token 训练不可能简单套用短上下文训练策略。论文提到两阶段 contextual parallelism,用于管理压缩注意力;还扩展 autograd 框架,支持 tensor-level checkpointing,从而更细粒度地控制重计算。它们共同服务于一个目标:在显存有限的情况下,把超长序列训练尽可能切分、复用和重计算,而不是让内存成为硬上限。
最后是推理框架中的 KV cache 结构和 on-disk storage。对于长上下文推理,KV cache 管理几乎和模型本身一样重要。DeepSeek-V4 的异构 KV cache 需要同时处理已压缩、未压缩、滑窗和不同注意力机制对应的状态;on-disk KV cache 则面向共享前缀复用,适合大量请求基于同一长文档或同一任务背景展开的场景。这部分能力如果实现成熟,会显著影响长上下文服务的实际成本。
图 5:DeepSeek-V4 的 KV cache 组织方式。论文中将 KV cache 拆成 CSA/HCA 的 classical KV cache,以及 SWA 和尚未压缩 token 对应的 state cache。
七、预训练与后训练:从基座能力到 reasoning effort
DeepSeek-V4 的训练流程分为预训练和后训练。预训练阶段,论文称 V4-Flash 使用 32T tokens,V4-Pro 使用 33T tokens,并且二者在预训练后就能原生支持 1M 长度上下文。基座模型评测中,V4-Flash-Base 在多个任务上超过 V3.2-Base,V4-Pro-Base 则进一步在知识密集任务、长上下文理解和多数推理代码任务上提升。
但现代大模型的最终能力越来越依赖后训练。DeepSeek-V4 的后训练包括 specialist training、on-policy distillation,以及面向不同 reasoning effort 的模式设计。论文中列出了 Non-Think、High、Max 等推理努力程度。可以把它理解为同一模型在不同预算下的工作模式:非思考模式更偏直接回答,高 reasoning effort 则允许模型投入更多推理计算,Max 模式追求更强能力上限。
图 6:DeepSeek-V4 系列的 thinking management。论文用它说明不同 reasoning effort 模式下模型如何管理思考预算。
这种设计反映了推理模型的一个重要趋势:能力不再只是训练完成后的固定点,而是和推理预算绑定。用户可以为简单任务选择更低成本模式,为复杂数学、代码、长文档分析或 agent 任务选择更高 reasoning effort。DeepSeek-V4-Pro-Max 被论文用作能力上限展示,DeepSeek-V4-Flash-Max 则体现较高性价比。
On-policy distillation 也值得关注。论文将 OPD 作为后训练中的重要环节,并讨论了 full-vocabulary OPD 的 teacher scheduling。直观来说,强 teacher 或高 effort 模式可以产生更高质量行为,再通过蒸馏让更低成本模型或模式吸收这些能力。对于模型系列化部署,这有现实意义:不可能所有请求都使用最高成本模式,如何把高成本推理中获得的能力迁移到更便宜的模型或模式,是提升整体服务效率的关键。
论文还提到 RL 和 OPD 基础设施,包括可抢占、容错的 rollout service,面向百万 token 上下文的 RL 框架,以及 agentic AI sandbox infrastructure。这里再次体现了 DeepSeek-V4 的系统取向:后训练不只是算法问题,还涉及大规模 rollout、工具执行、安全隔离、失败恢复和资源调度。尤其是 agent 任务,模型会调用 Bash、搜索、代码执行等工具,训练和评测环境本身就必须足够可靠。
八、评测结果:强表现与需要谨慎解读的边界
下面几张表不是完整复刻论文所有 benchmark,而是把与本文主线最相关的结果抽出来:模型规格与基座能力、长上下文效率、中文写作、白领任务和 coding agent。完整结果仍应以原论文表格为准。
表 2:基座模型关键结果节选,来自论文 Table 1。原表覆盖更多知识、语言、推理、代码、数学与长上下文 benchmark。
表 3:1M token 场景下的效率对比,来自论文摘要与 Introduction。
论文报告中,DeepSeek-V4-Pro-Max 在标准 benchmark 上表现突出,尤其被描述为开放模型中的新强基线。V4 系列覆盖了知识、数学、代码、长上下文、agent 等多个方向。根据论文表格,V4-Pro-Base 在 MMLU、MMLU-Pro、Simple-QA verified、FACTS Parametric、LongBench-V2 等多项基座评测中相对 V3.2-Base 和 V4-Flash-Base 有明显提升;V4-Flash-Base 则以更小激活参数在不少任务上超过 V3.2-Base。
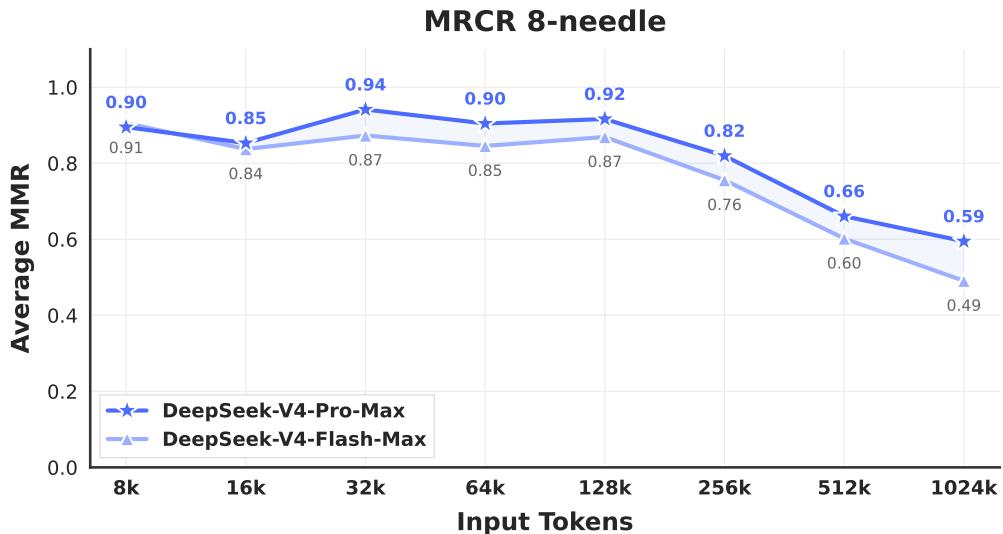
对于长上下文,论文展示了 MRCR 等任务结果,并强调 V4 系列在百万 token 场景下的效率优势。这里的解读重点不应只是“分数更高”,而是“模型是否在更低 cache 和计算成本下保持长上下文能力”。如果只追求 benchmark 分数,长上下文模型可能仍然难以经济部署;如果能同时降低边际推理成本,长上下文才更可能成为日常能力。
图 7:DeepSeek-V4 系列在 MRCR 任务上的表现。
在真实任务部分,论文讨论了中文写作、搜索、白领任务和 coding agent。中文写作方面,附录表格显示,DeepSeek-V4-Pro 与 Gemini-3.1-Pro 的对比中,在功能写作总计 3170 个样本上,DeepSeek 一侧胜率为 62.65%,Gemini 为 34.10%,平局为 3.25%;在创意写作总计 2837 个样本上,指令遵循维度 DeepSeek 为 60.03%,Gemini 为 39.44%,平局为 0.53%,写作质量维度 DeepSeek 为 77.48%,Gemini 为 22.35%,平局为 0.18%。这些数字说明论文内部评测认为 V4-Pro 在中文写作质量上有明显优势,但也要注意,这是论文提供的比较设置。
表 4:中文写作评测节选,来自论文附录 Table 12 和 Table 13。
搜索任务方面,论文区分了 agentic search 和 retrieval augmented search,并在附录中比较了成本和效果。它想表达的方向是:当模型具备更长上下文和更强工具使用能力后,搜索不只是检索几段材料再回答,而可以变成多轮查询、比较、验证和综合的过程。这与百万 token 上下文能力是相互促进的:更长上下文允许模型保留更多搜索中间结果,更强 agent 能力则让模型更主动地构造信息获取路径。
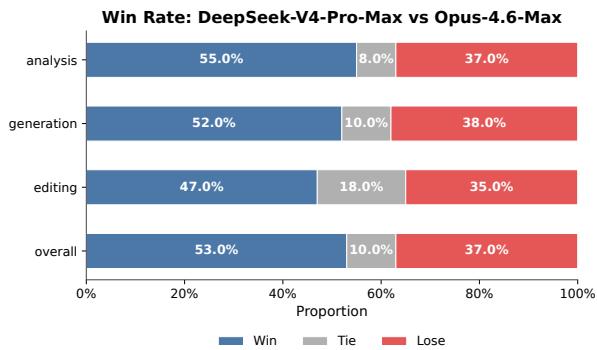
白领任务评测中,论文称 DeepSeek-V4-Pro-Max 相对 Opus-4.6-Max 在多类中文办公任务上取得 63% 的 non-loss rate,并在任务完成度和内容质量上表现较强。论文同时也指出了一些不足:在指令遵循上偶尔遗漏特定格式约束,在压缩长文本为简洁摘要方面不够强,PPT 等视觉呈现的格式美观度仍有提升空间。相比只列胜率,这些缺点更有参考价值,因为它们说明模型并非在所有办公细节上都已经成熟。
图 8:论文中的中文白领任务评测图。
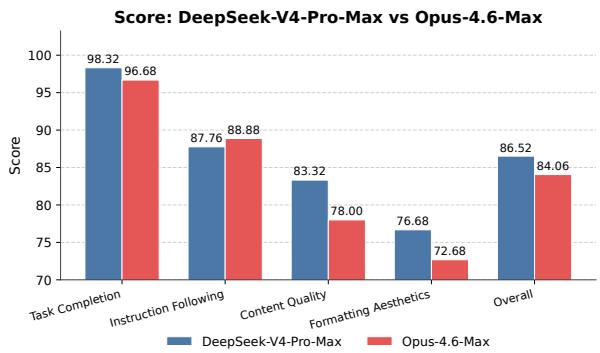
Coding agent 部分,论文从内部真实研发工作中收集约 200 个挑战任务,经筛选保留 30 个作为评测集,覆盖功能开发、bug 修复、重构和诊断,技术栈包括 PyTorch、CUDA、Rust 和 C++ 等。表 8 显示,DeepSeek-V4-Pro-Max 在该内部 R&D Coding Benchmark 上 pass rate 为 67%,高于 Claude Sonnet 4.5 的 47%,接近 Claude Opus 4.5 的 70%,低于 Opus 4.5 Thinking 的 73% 和 Opus 4.6 Thinking 的 80%。论文还报告了对 85 位 DeepSeek 开发者和研究员的调查:52% 认为 V4-Pro 已准备好作为默认主力 coding model,39% 倾向于是,少于 9% 表示否;反馈中的问题包括小错误、对模糊提示的误解和偶发过度思考。
表 5:内部 R&D Coding Benchmark 结果,来自论文 Table 8。论文说明外部模型仅用于评测对比。
这些结果整体上支持一个判断:DeepSeek-V4 的能力叙事并不局限在传统问答,而是明显面向 agentic workflow。长上下文、工具调用、代码仓库理解、文档生成、多轮搜索和推理预算管理,正在汇合成同一类应用形态。但也正因为如此,评测边界更需要谨慎。内部研发任务、内部办公任务和人工偏好评测都很有价值,却不等同于完全开放、可复现、跨组织的第三方结论。
九、DeepSeek-V4 的技术意义:把长上下文做成成本问题,而不是炫技问题
如果要用一句话概括 DeepSeek-V4 的意义,我认为它不是“又一个支持百万 token 的模型”,而是“把百万 token 上下文重新表述为效率工程问题”。这两者差别很大。前者强调规格,后者强调可持续使用。对于实际应用来说,窗口长度只是入场券;真正决定使用频率的是单位成本、延迟、稳定性、cache 复用和不同任务预算之间的切换能力。
从这个角度看,DeepSeek-V4 的几条技术线是相互咬合的。CSA/HCA 降低长序列注意力和 KV 成本;mHC 提升深层模型的信号传播稳定性;Muon 改善训练收敛和稳定性;FP4 降低专家参数相关的存储和潜在计算压力;MoE 通信计算重叠、TileLang、确定性 kernel、contextual parallelism 和 on-disk KV cache 则把这些模型设计变成可训练、可推理、可服务的系统。
这种“模型-系统共同设计”的趋势会越来越重要。早期大模型论文常常把重点放在模型结构和训练数据规模上,系统工程更多隐藏在实现细节里。但当模型进入万亿参数、百万上下文、agent 工具调用和多种 reasoning effort 并存的阶段,系统工程本身已经成为能力的一部分。一个模型是否强,不再只取决于参数和数据,也取决于它能否在真实服务中低成本地保留长历史、复用 cache、稳定并行训练、处理工具调用失败,并在不同预算下输出合理结果。
DeepSeek-V4 也体现了一个更细的趋势:未来模型竞争可能不再只是“最大模型之间”的竞争,而是“模型系列的成本分层”竞争。Pro 负责能力上限,Flash 负责高性价比;Max/High/Non-Think 等模式负责推理预算分层;蒸馏和 OPD 负责在不同层级之间迁移能力。对用户来说,理想状态不是每次都调用最贵模型,而是系统根据任务复杂度选择合适预算。DeepSeek-V4 的论文虽然没有完整展开产品调度策略,但它提供的模型系列和后训练模式已经朝这个方向移动。
十、仍需观察的局限
客观地看,DeepSeek-V4 论文也有几个需要继续观察的地方。
第一,它是 preview version。Preview 通常意味着模型、系统、评测和接口仍可能继续变化。论文给出的能力和效率结果很有参考价值,但实际开发者体验还需要在更大规模用户场景中验证,尤其是百万 token 上下文的稳定性、延迟、成本和边界行为。
第二,部分关键评测依赖内部框架或内部任务集。内部评测的优点是贴近真实业务,尤其 coding agent 和白领任务很难用传统 benchmark 覆盖;但它的缺点是外部读者难以复现,也难以判断任务分布、评分标准和对比模型设置是否完全公平。因此,更稳妥的表述是:论文报告了强表现,并提供了值得关注的信号,但最终仍需要开放评测和真实用户反馈补充验证。
第三,长上下文能力不等于长上下文可靠性。模型能读取百万 token,并不保证它总能在百万 token 中稳定定位细节、避免遗忘、抵抗干扰或进行严谨引用。压缩注意力尤其需要在效率和细节保真之间做权衡。DeepSeek-V4 的 CSA/HCA 设计显然在试图平衡这个问题,但真实场景中的长文档问答、代码库修改、法律合同审查等任务,仍然需要更细粒度的可靠性测试。
第四,论文自己也提到一些实际短板。例如在白领任务中,模型在指令遵循上偶尔会遗漏特定格式要求;在长文本压缩摘要上不够擅长;在演示文稿等视觉格式美观度上仍有提升空间。Coding agent 调查中也出现了小错误、误解模糊提示和偶发过度思考的问题。这些问题并不否定模型能力,但提醒我们:agentic AI 的最后一公里往往不在单次推理分数,而在稳定、可控、符合人类工作习惯。
结语:百万上下文之后,竞争焦点会转向“可用的长程智能”
DeepSeek-V4 的论文给出的最重要信号,是长上下文竞争正在从“窗口长度”转向“长程智能的单位经济性”。当模型可以把一百万 token 放进上下文,下一步问题自然变成:它能否低成本地读完?能否准确找到关键证据?能否在多轮工具调用中保持状态?能否把长文档、代码库和历史任务转化为可靠行动?能否根据任务难度自动调节 reasoning effort?
DeepSeek-V4 的回答,是用混合注意力、mHC、Muon、FP4、MoE 系统优化和 KV cache 工程搭建一条效率路线。论文报告的结果显示,这条路线在基座能力、后训练推理、长上下文和部分真实任务上都取得了可观进展。尤其是 V4-Pro 与 V4-Flash 的组合,让能力上限和性价比之间有了更清晰的分工。
但它也不是终点。百万 token 上下文只是打开了更长任务的入口,真正困难的是让模型在超长、开放、多工具、多轮反馈的环境中持续可靠地工作。DeepSeek-V4 的价值,恰恰在于把这个问题从概念层面推进到了系统实现层面:不再只是问模型能不能“装下”更多内容,而是问模型能不能以更低成本、更稳定方式,把长上下文变成可用的推理和行动能力。
如果后续开放模型能沿着这条路线继续迭代,长上下文可能会从少数高端模型的展示能力,逐步变成复杂知识工作和 agent 应用的默认基础设施。到那时,真正的竞争不只是“谁的窗口更长”,而是谁能在长窗口里更便宜、更准确、更可靠地完成任务。