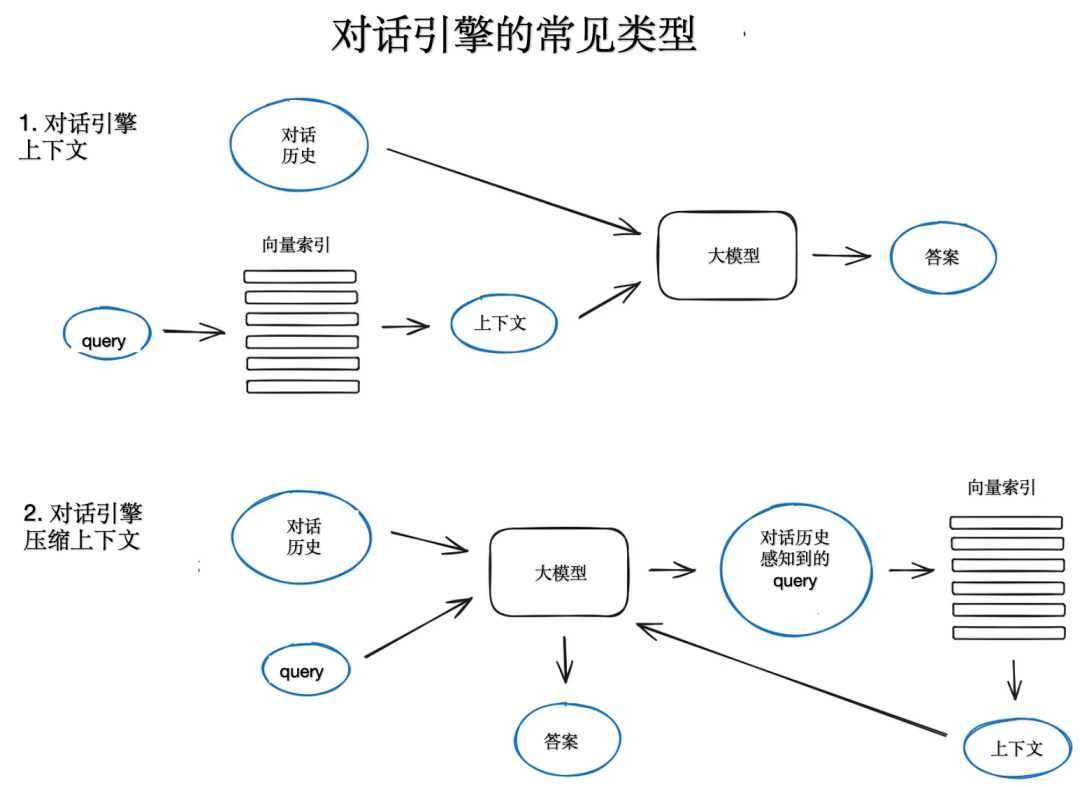
构建一个可以在单个查询中多次运行RAG系统的一个重要特性是聊天逻辑,考虑到对话上下文,就像在 LLM 时代之前的经典聊天机器人一样。这是支持后续问题,重复指代,或任意用户命令相关的以前对话上下文所必需的。查询压缩技术可以同时考虑聊天上下文和用户查询。
有几种方法可以实现上下文压缩:
一种流行且相对简单的 ContextChatEngine,首先检索与用户查询相关的上下文,然后将其连同聊天历史从存缓发送给 LLM,让 LLM 在生成下一个答案时能够意识到前一个上下文。
另一种更复杂的实现是 CondensePlusContextMode,在每次交互中,聊天历史记录和最后一条消息被压缩成一个新的查询(这个查询是由模型自行生成的),然后这个查询进入索引,检索到的上下文被传递给 LLM连同原始用户消息来生成一个答案。