什么是Elasticsearch?
Elasticsearch是一个开源的分布式、RESTful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库——无论是开源还是私有,但它也仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理,因为Lucene 非常复杂。 为了解决Lucene使用时的繁复性,于是Elasticsearch便应运而生。它使用 Java 编写,内部采用 Lucene 做索引与搜索,但是它的目标是使全文检索变得更简单,简单来说,就是对Lucene 做了一层封装,它提供了一套简单一致的 RESTful API 来帮助我们实现存储和检索。 当然,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确地形容:
- 一个分布式的实时文档存储,每个字段可以被索引与搜索;
- 一个分布式实时分析搜索引擎;
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
由于Elasticsearch的功能强大和使用简单,维基百科、卫报、Stack Overflow、GitHub等都纷纷采用它来做搜索。现在,Elasticsearch已成为全文搜索领域的主流软件之一。
专业术语
节点 node
节点是属于集群的Elasticsearch的运行实例 。可以在单个服务器上启动多个节点,但是通常每个服务器应该有一个节点。在启动时,节点将使用单播来发现具有相同集群名称的现有集群,并将尝试加入该集群
索引 index
索引就像关系数据库中的表。它具有一个包含type的 映射,该type包含索引中的字段。索引是一个逻辑名称空间,它映射到一个或多个 主分片,并且可以具有零个或多个 副本分片。
文档 document
文档是JSON对象(在其他语言中也称为hash / hashmap /关联数组),其中包含零个或多个 字段或键-值对。被索引的原始JSON文档将存储在 _source字段中,该字段在获取或搜索文档时默认返回。
字段 field
一个文件包含字段或键-值对的列表。该值可以是简单(标量)值(例如,字符串,整数,日期),也可以是嵌套结构(如数组或对象)。字段类似于关系数据库中表中的列。所述映射用于每个字段具有一个字段类型(不要与文件相混淆类型),其指示可以被存储在该字段中的数据,例如类型integer,string, object。该映射还允许您定义(除其他事项外)应如何分析字段的值。
ID 每个文档id唯一
文档 的ID 标识文档。该 index/id文件中必须是唯一的。如果没有提供ID,则会自动生成。
映射 mapping
映射就像关系数据库中的架构定义。每个 索引都有一个映射,该映射定义一个type,以及许多索引范围的设置。
映射可以明确定义,也可以在为文档建立索引后自动生成。
过滤 filter
过滤器是不计分的查询,表示它不对文档进行计分。它只关心回答问题“此文档是否匹配?”。答案始终是简单的二进制“是”或“否”。这种查询据说是在过滤器上下文中进行的,因此称为过滤器。过滤器是对集合包含或排除的简单检查。在大多数情况下,过滤的目的是减少必须检查的文档数量。
类型 type
用于表示文档类型的类型,例如an email,a user或a tweet。类型已弃用,正在删除中。7.x只保留了_doc类型,8.0以后将彻底删除类型。
本项目中的应用
版本
本项目使用了7.9.3版本
pom.xml
<!--elasticsearch-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>7.9.3</version>
</dependency>
分词插件
本项目使用的分词插件为
elasticsearch-analysis-ik #版本7.9.3
elasticsearch-analysis-pinyin #版本7.9.3
拼音分词的实现
拼音分词的方法有两种,第一种是利用过滤器,将中文分词插件ik分词之后的结果进行拼音分词,这种方式我尝试了几次,结果并不符合我的预期,所以又想出了第二种简单的方法。
实现方式:
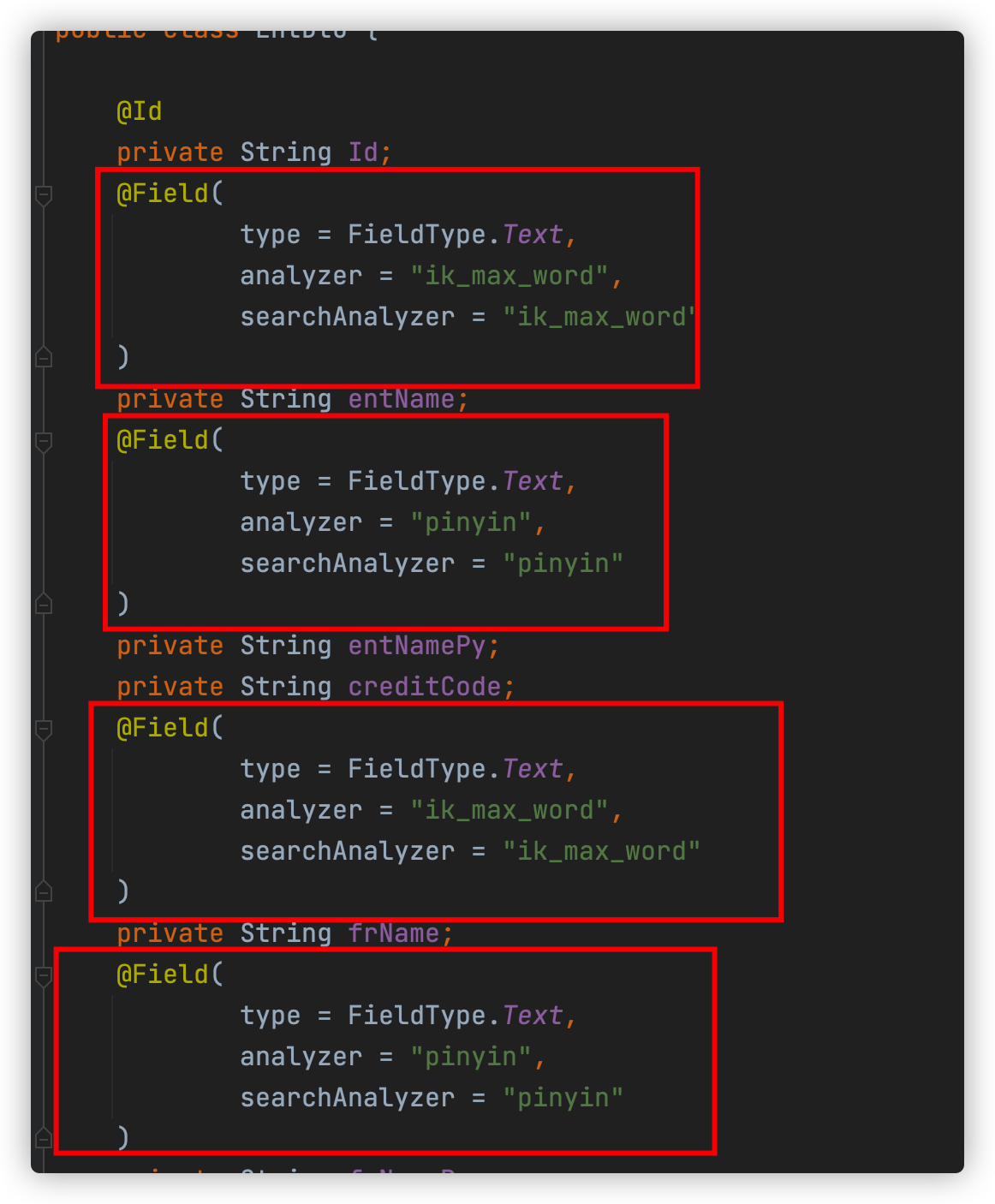
查看pce/pce-credit/pce-credit-biz/src/main/java/blog/lucent/pce/credit/dto/EntDto.java
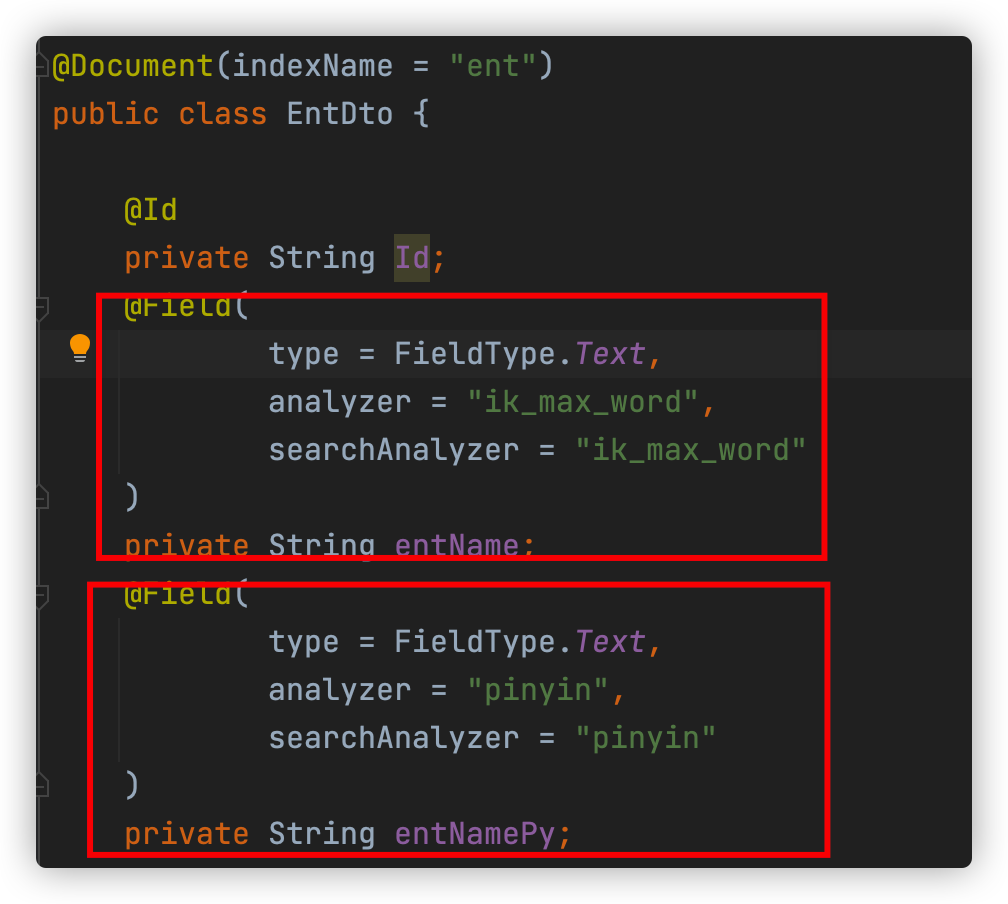
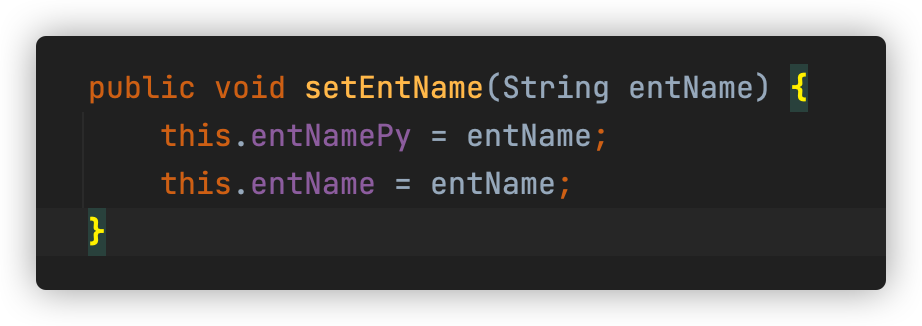
设置两个完全相同的字段,并指定不同的分词器,一个用于中文分词,一个用于拼音分词,搜索时只需要根据不同的条件搜索不同的字段即可,搜索引擎会根据初始创建的映射使用对应的分词器进行分词。

我们的项目只需要手动安装Elasticsearch和分词插件即可,映射(mapping)会在第一次启动时自动创建。
所以一定要先安装好分词插件再启动项目。
代码如下:
管理
Elasticsearch可以使用kibana可视化工具进行管理。
Elasticsearch也可以使用DSL进行管理,就相当于用sql语句查询数据库,例如:
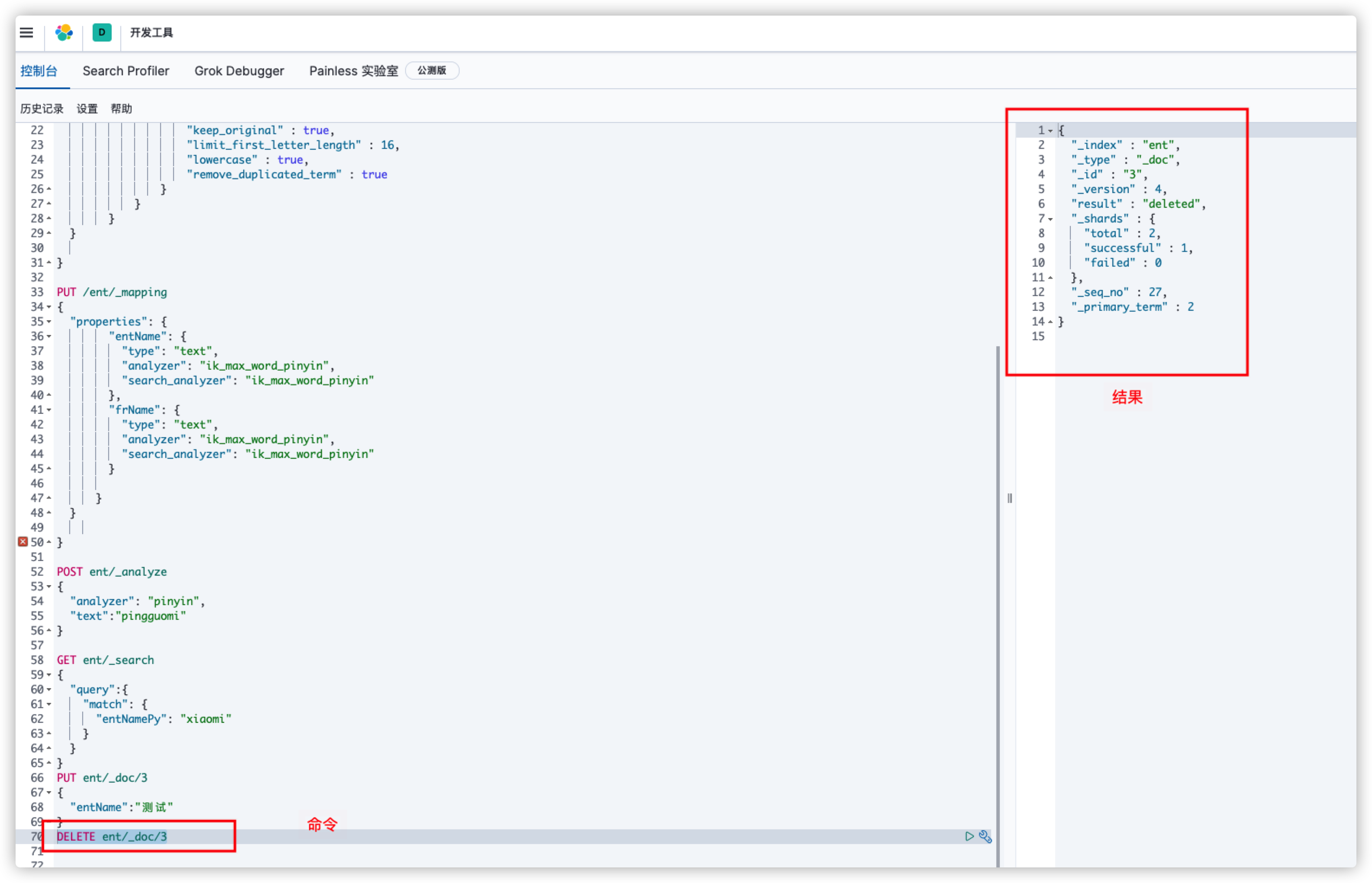
GET ent/_search
{
"query": {
"match" : {
"entName" : "this is a test"
}
}
}
#这是一条简单的查询语句
PUT /ent/_mapping
{
"properties": {
"entName": {
"type": "text",
"analyzer": "ik_max_word_pinyin",
"search_analyzer": "ik_max_word_pinyin"
},
"frName": {
"type": "text",
"analyzer": "ik_max_word_pinyin",
"search_analyzer": "ik_max_word_pinyin"
}
}
}
#设置索引ent的映射,其中指定了每个字段的类型和分词器
#向索引ent中插入一条数据(_doc后面的3是指定的id,不指定则自动生成)
PUT ent/_doc/3
{
"entName":"测试"
}
#删除一条数据
DELETE ent/_doc/3
{
}
#以上两条命令区别仅仅是请求方式一个put一个delete,搜索引擎会根据不同请求方式执行不同命令
这些命令都可以在shell中执行,但是kibana提供了更好用的命令行控制台。