
千问3已经发布几天了,华为公开最新的Mindeie镜像,我们可以暂时使用vllm-ascend进行推理
下载镜像
docker pull quay.io/ascend/vllm-ascend:v0.8.4rc2下载模型
我们这里以Qwen3-32B为例,其它模型同理
权重在这里下载: https://www.modelscope.cn/models/Qwen/Qwen3-32B
下载到你想要的位置
编写启动命令
docker run --rm -d \
--name Qwen3-32B \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-v /data/4pd-workspace/models/Qwen3-32B:/data1/Qwen3-32B:ro \
-p 18034:8000 \
-e PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256 \
quay.io/ascend/vllm-ascend:v0.8.4rc2 \
vllm serve /data1/Qwen3-32B --max_model_len 32768 -tp 4 --served-model-name Qwen3-32B解释
vllm serve /data1/Qwen3-32B 启动推理的命令,后面是模型权重路径
--max_model_len 32768 指定上下文长度32k
-tp 4 指定4卡推理,其实2卡就够,看你需要
--served-model-name Qwen3-32B 指定推理服务的模型名称
-v /data/4pd-workspace/models/Qwen3-32B:/data1/Qwen3-32B:ro 映射模型权重路径
-p 18034:8000 映射端口,vllm内部默认使用了8000端口推理
启动
执行上面的命令后,我们可以查看容器状态
docker ps |grep Qwen3-32B
测试
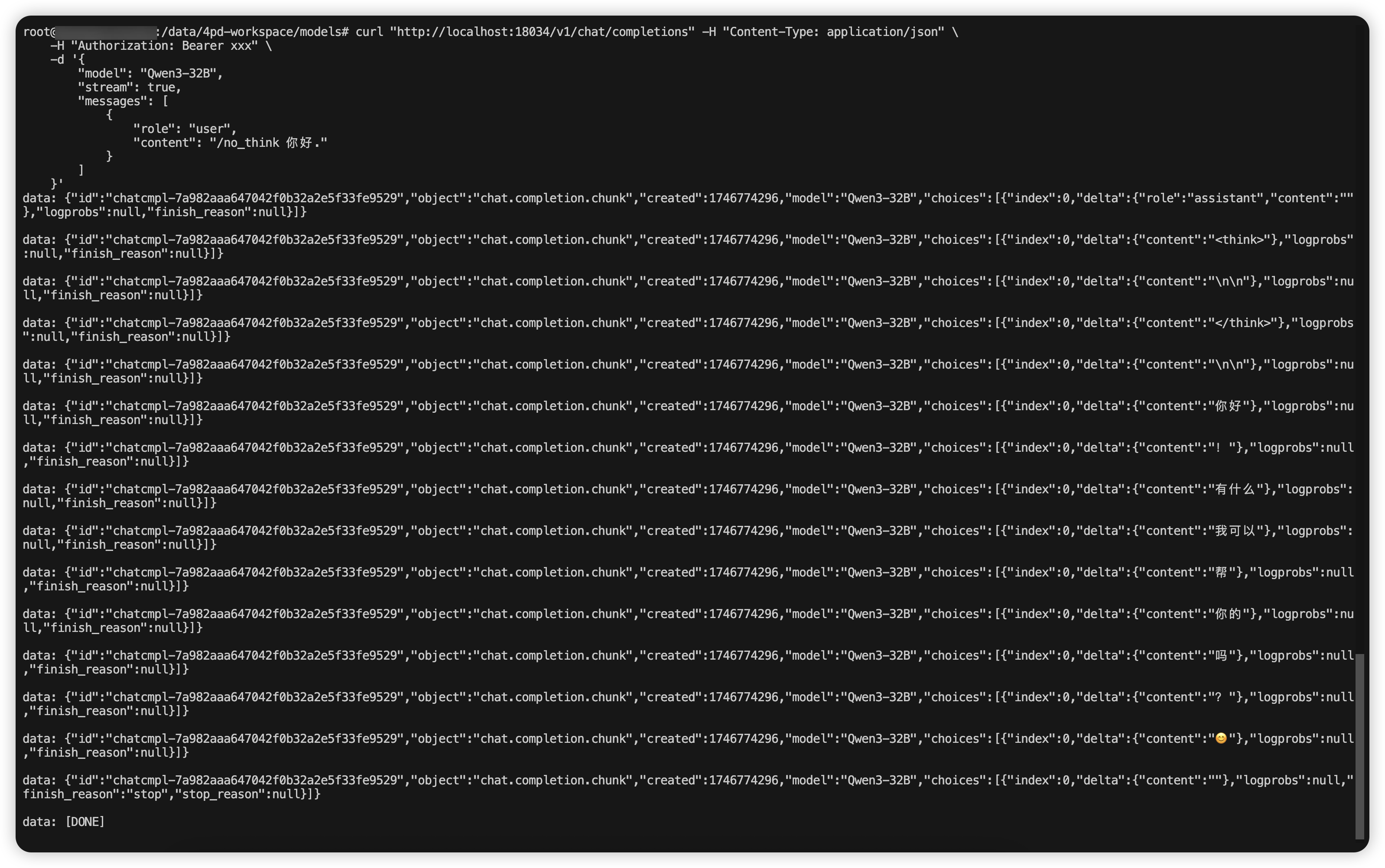
curl "http://localhost:18034/v1/chat/completions" -H "Content-Type: application/json" \
-H "Authorization: Bearer xxx" \
-d '{
"model": "Qwen3-32B",
"stream": true,
"messages": [
{
"role": "user",
"content": "/no_think 你好."
}
]
}'
至此,使用vllm-ascend在昇腾910B上部署千问3已经成功