
终于拿到了华为的最新版本Mindie镜像
mindie_2.0.T17.B010-800I-A2-py3.11-openeuler24.03-lts-aarch64.tar.gz
终于可以在昇腾平台上部署Qwen3了
Qwen3简介
Qwen3是Qwen系列中最新一代的大型语言模型,提供了密集和混合专家(MoE)模型的全面套件。基于广泛的训练,Qwen3在推理、指令遵循、代理功能和多语言支持方面取得了很大的进展,主要具有以下功能:
思维模式(用于复杂的逻辑推理、数学和编码)和非思维模式(用于高效、通用的对话)在单个模型内无缝切换,确保跨各种场景的最佳性能。
增强了推理能力在数学、代码生成和常识逻辑推理方面超过了之前的QwQ(思维模式)和Qwen2.5(非思维模式)。
人类偏好调整,擅长创意写作、角色扮演、多轮对话和指令跟随,提供更自然、更吸引人、更沉浸式的对话体验。
在代理能力方面的专业知识,能够在思考模式和非思考模式下与外部工具精确集成,在基于代理的复杂任务中实现开源模型中的领先性能。
支持100多种语言和方言*具有强大多语言教学能力和翻译能力。
物料准备
模型
我们这里以Qwen3-32B为例,其它模型同理
权重在这里下载: https://www.modelscope.cn/models/Qwen/Qwen3-32B
下载到你想要的位置
推理引擎
我们使用刚拿到的 mindie_2.0.T17.B010-800I-A2-py3.11-openeuler24.03-lts-aarch64.tar.gz
使用docker加载镜像:
docker load -i mindie_2.0.T17.B010-800I-A2-py3.11-openeuler24.03-lts-aarch64.tar.gz建立推理容器
启动容器
# 我们这里使用4卡启动,其实两卡也没问题
docker run -it -d --shm-size=1g \
--privileged \
--name mindie-Qwen3-32B \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--net=host \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v /data/4pd-workspace/models/Qwen3-32B:/data/Qwen3-32B:ro \ # 这里是模型的权重路径,改成你自己的
mindie:2.0.T17.B010-800I-A2-py3.11-openeuler24.03-lts-aarch64 bash设置容器
进入容器
docker exec -it mindie-Qwen3-32B bash更新transformers,因为Qwen3需要使用新版本的transformers
pip install --upgrade transformers==4.51.0 -i https://pypi.tuna.tsinghua.edu.cn/simple修改服务化推理的配置文件
vim /usr/local/Ascend/mindie/latest/mindie-service/conf/config.json这是我改好的
{
"Version": "1.0.0",
"ServerConfig": {
"ipAddress": "0.0.0.0",
"managementIpAddress": "127.0.0.2",
"port": 18025,
"managementPort": 18026,
"metricsPort": 18027,
"allowAllZeroIpListening": true,
"maxLinkNum": 1000,
"httpsEnabled": false,
"fullTextEnabled": false,
"tlsCaPath": "security/ca/",
"tlsCaFile": [
"ca.pem"
],
"tlsCert": "security/certs/server.pem",
"tlsPk": "security/keys/server.key.pem",
"tlsPkPwd": "security/pass/key_pwd.txt",
"tlsCrlPath": "security/certs/",
"tlsCrlFiles": [
"server_crl.pem"
],
"managementTlsCaFile": [
"management_ca.pem"
],
"managementTlsCert": "security/certs/management/server.pem",
"managementTlsPk": "security/keys/management/server.key.pem",
"managementTlsPkPwd": "security/pass/management/key_pwd.txt",
"managementTlsCrlPath": "security/management/certs/",
"managementTlsCrlFiles": [
"server_crl.pem"
],
"kmcKsfMaster": "tools/pmt/master/ksfa",
"kmcKsfStandby": "tools/pmt/standby/ksfb",
"inferMode": "standard",
"interCommTLSEnabled": true,
"interCommPort": 18121,
"interCommTlsCaPath": "security/grpc/ca/",
"interCommTlsCaFiles": [
"ca.pem"
],
"interCommTlsCert": "security/grpc/certs/server.pem",
"interCommPk": "security/grpc/keys/server.key.pem",
"interCommPkPwd": "security/grpc/pass/key_pwd.txt",
"interCommTlsCrlPath": "security/grpc/certs/",
"interCommTlsCrlFiles": [
"server_crl.pem"
],
"openAiSupport": "vllm",
"tokenTimeout": 600,
"e2eTimeout": 600,
"distDPServerEnabled": false
},
"BackendConfig": {
"backendName": "mindieservice_llm_engine",
"modelInstanceNumber": 1,
"npuDeviceIds": [
[
0,
1,
2,
3
]
],
"tokenizerProcessNumber": 8,
"multiNodesInferEnabled": false,
"multiNodesInferPort": 1120,
"interNodeTLSEnabled": true,
"interNodeTlsCaPath": "security/grpc/ca/",
"interNodeTlsCaFiles": [
"ca.pem"
],
"interNodeTlsCert": "security/grpc/certs/server.pem",
"interNodeTlsPk": "security/grpc/keys/server.key.pem",
"interNodeTlsPkPwd": "security/grpc/pass/mindie_server_key_pwd.txt",
"interNodeTlsCrlPath": "security/grpc/certs/",
"interNodeTlsCrlFiles": [
"server_crl.pem"
],
"interNodeKmcKsfMaster": "tools/pmt/master/ksfa",
"interNodeKmcKsfStandby": "tools/pmt/standby/ksfb",
"ModelDeployConfig": {
"maxSeqLen": 32768,
"maxInputTokenLen": 32768,
"truncation": false,
"ModelConfig": [
{
"modelInstanceType": "Standard",
"modelName": "Qwen3-32B",
"modelWeightPath": "/data/Qwen3-32B",
"worldSize": 4,
"cpuMemSize": 5,
"npuMemSize": -1,
"backendType": "atb",
"trustRemoteCode": false
}
]
},
"ScheduleConfig": {
"templateType": "Standard",
"templateName": "Standard_LLM",
"cacheBlockSize": 128,
"maxPrefillBatchSize": 50,
"maxPrefillTokens": 32768,
"prefillTimeMsPerReq": 150,
"prefillPolicyType": 0,
"decodeTimeMsPerReq": 50,
"decodePolicyType": 0,
"maxBatchSize": 200,
"maxIterTimes": 32768,
"maxPreemptCount": 0,
"supportSelectBatch": false,
"maxQueueDelayMicroseconds": 5000
}
}
}配置文件的注意点
ipAddress如果是0.0.0.0 需要allowAllZeroIpListening=true
worldSize要和npuDeviceIds 匹配。他们用来控制多卡并行推理。npuDeviceIds通常指的是逻辑卡(不管怎么挂卡都是0,1,2...这样的id)。但是如果你的容器是--privileged的话全部卡都会挂进来,那它就得指实体卡id的。
如果没证书 httpsEnabled要关上
maxPrefillTokens >= maxSeqLen > maxInputTokenLen
maxIterTimes 会限制迭代次数。如果很小,可能模型会戛然而止。如果不想特别设置最好和 maxSeqLen一致
启动推理
如果上面的操作都正确,那么我们就可以启动推理服务了
# 进入启动路径
cd /usr/local/Ascend/mindie/latest/mindie-service/bin/
# 启动推理服务
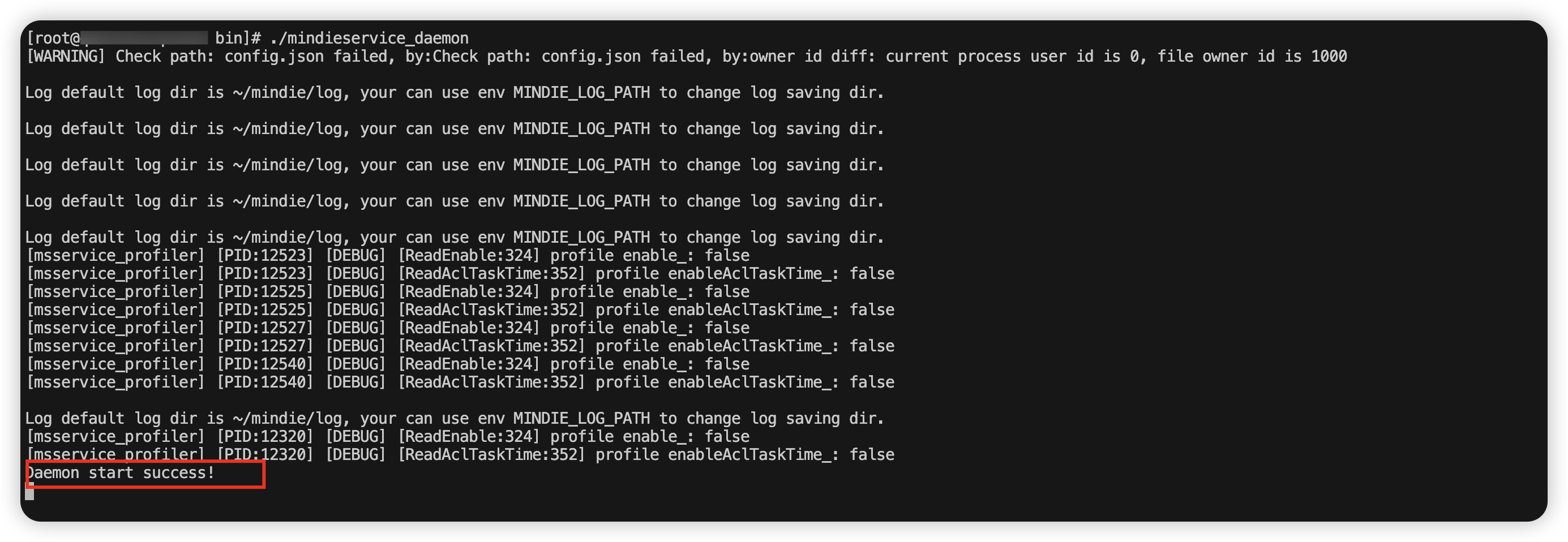
./mindieservice_daemon当你看到如下截图所示,即服务启动成功
测试
我们直接调用服务进行测试
curl "http://localhost:18025/v1/chat/completions" -H "Content-Type: application/json" \
-H "Authorization: Bearer xxx" \
-d '{
"model": "Qwen3-32B",
"stream": true,
"messages": [
{
"role": "user",
"content": "/no_think 你好."
}
]
}'结果
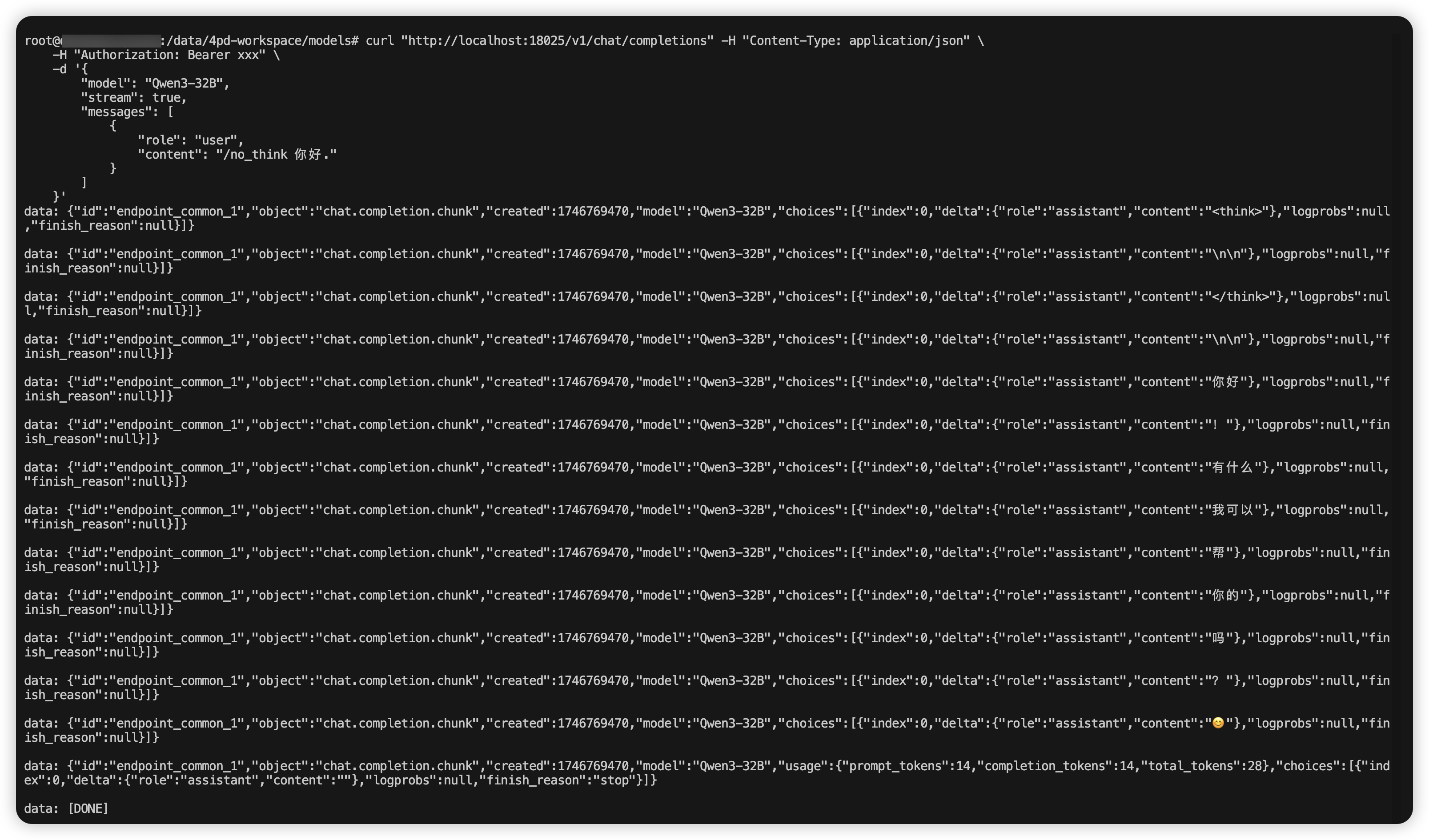
可以看到,推理正常,至此Qwen3部署成功
写在后面
虽然我们经过一番折腾,成功把Qwen3-32B运行起来,但是如果换个其它模型,是不是还要重新做一遍上面的操作?是不是还要重新配置一下那个复杂的配置文件?
所以我们需要利用这个容器,制作一个专门用于我们推理的镜像,具体步骤写在下个文章