
上一个文章,我们已经成功在昇腾910B平台上部署了Qwen3,现在我们就利用已经配置好环境的容器,制作一个专门方便部署的推理镜像
制作镜像
编写python脚本用来自动设置推理配置文件
vim /usr/local/Ascend/update_mindie_config.py在文件中写入下面的代码
import sys
import json
import argparse
import os
parser = argparse.ArgumentParser(description="")
parser.add_argument("--model",type=str, required=True, help="模型路径")
parser.add_argument("--served-model-name",type=str, required=True, help="模型名字")
parser.add_argument("--tensor-parallel-size",type=int, default=1, help="tensor并行")
parser.add_argument("--host",type=str, default="0.0.0.0", help="服务host")
parser.add_argument("--port",type=int, default=8000, help="服务端口")
parser.add_argument("--max-model-len",type=int, default=0, help="max sequece length")
DEFAULT_MAX_SEQENCE_LENGTH=1024
# MINDIE_CONFIG_FILE_PATH="config_example/mindie_config.json"
# MINDIE_CONFIG_FILE_PATH="/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json"
MINDIE_CONFIG_FILE_PATH=os.environ.get("MINDIE_CONFIG_FILE_PATH","/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json")
def main(args):
# 原始congig
with open(MINDIE_CONFIG_FILE_PATH,'r') as f:
mind_ie_config = json.load(f)
# 输入参数
parsed_args = parser.parse_args(args)
# ServerConfig
mind_ie_config["ServerConfig"]["ipAddress"]=parsed_args.host
mind_ie_config["ServerConfig"]["allowAllZeroIpListening"]=True
mind_ie_config["ServerConfig"]["port"]=parsed_args.port
# tls先关上
mind_ie_config["ServerConfig"]["httpsEnabled"]=False
# ModelDeployConfig
# 模型长度配置
model_path = parsed_args.model
if model_path.endswith("/"):
model_path = model_path[:-1]
if parsed_args.max_model_len == 0:
try:
with open(f"{model_path}/tokenizer_config.json","r") as f:
tokenizer_config = json.load(f)
parsed_args.max_model_len = tokenizer_config.get("model_max_length", 0)
if parsed_args.max_model_len!=0:
print("get max_model_len from tokenizer_config.json key:model_max_length",parsed_args.max_model_len)
except Exception as e:
print(e)
pass
if parsed_args.max_model_len == 0:
try:
with open(f"{model_path}/config.json","r") as f:
model_config = json.load(f)
parsed_args.max_model_len = model_config.get("max_position_embeddings", 0)
if parsed_args.max_model_len!=0:
print("get max_model_len from config.json key:max_position_embeddings",parsed_args.max_model_len)
except Exception as e:
print(e)
pass
if parsed_args.max_model_len == 0:
parsed_args.max_model_len = DEFAULT_MAX_SEQENCE_LENGTH
print("not max_model_len set. use default value",parsed_args.max_model_len)
# mindie要求Other Users对config文件权限为0
model_config_json = f"{parsed_args.model}/config.json"
os.chmod(model_config_json, 0o640)
print(f"设置{model_config_json}文件权限640")
mind_ie_config["BackendConfig"]["ModelDeployConfig"]["ModelConfig"][0]["modelName"]=parsed_args.served_model_name
mind_ie_config["BackendConfig"]["ModelDeployConfig"]["ModelConfig"][0]["modelWeightPath"]=parsed_args.model
mind_ie_config["BackendConfig"]["ModelDeployConfig"]["ModelConfig"][0]["worldSize"]=parsed_args.tensor_parallel_size
mind_ie_config["BackendConfig"]["ModelDeployConfig"]["maxSeqLen"]=parsed_args.max_model_len
#这个先和max_model_len弄成一致的
maxInputToken=parsed_args.max_model_len
mind_ie_config["BackendConfig"]["ModelDeployConfig"]["maxInputTokenLen"]=maxInputToken
#maxPrefillTokens
mind_ie_config["BackendConfig"]["ScheduleConfig"]["maxPrefillTokens"]=parsed_args.max_model_len
# 推测这个太小模型会戛然而停止
mind_ie_config["BackendConfig"]["ScheduleConfig"]["maxIterTimes"]=parsed_args.max_model_len
# BackendConfig
# NPU卡指定 "npuDeviceIds" : [[0,1]]。 这个配置我们是按可见卡逻辑序号来设置的0,1,2...
# 这里要求我们的卡挂进机器之后要变成逻辑ID
# 比如要挂4,5卡 在容器里看是0,1卡。所以docker启动必须用: -e ASCEND_VISIBLE_DEVICES=4,5 挂卡
# 而不能只 --/dev/davinci4 \ --/dev/davinci5 \
# 而且不能直接开 --privileged=true 不然全部卡都会进来,这样npuDeviceIds就得设置真实卡ID了。就不能简单 0,1,2 ...设置了
# k8s的话应该默认就是逻辑序号不需要特别注意
npu_divice_ids = []
for i in range (0,parsed_args.tensor_parallel_size):
npu_divice_ids.append(i)
mind_ie_config["BackendConfig"]["npuDeviceIds"]=[npu_divice_ids]
print("==============mindie配置文件===============")
print(json.dumps(mind_ie_config))
print("====================================")
with open(MINDIE_CONFIG_FILE_PATH,'w') as f:
output = json.dumps(mind_ie_config)
f.write(output)
if __name__ == "__main__":
args = sys.argv[1:]
main(args)编写启动脚本
vim /usr/local/Ascend/entrypoint.sh在文件中加入下面的代码
#!/bin/bash
cd /usr/local/Ascend
echo "参数:"
echo "$@"
# 同步 /root/.bashrc 的设置。可能有更好的方式
export LD_LIBRARY_PATH=/usr/local/Ascend/driver/lib64/driver:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/usr/local/Ascend/driver/lib64/common:$LD_LIBRARY_PATH
# export LANG=en_US.UTF-8 # 这些在旧版本的Mindie 中有用,这个新版本会报错
# export LANGUAGE=en_US:en # 这些在旧版本的Mindie 中有用,这个新版本会报错
# export LC_ALL=en_US.UTF-8 # 这些在旧版本的Mindie 中有用,这个新版本会报错
echo "set ascend-toolkit"
source /usr/local/Ascend/ascend-toolkit/set_env.sh
echo "set atb"
source /usr/local/Ascend/nnal/atb/set_env.sh
echo "set mindie"
source /usr/local/Ascend/mindie/set_env.sh
echo "set llm_model"
source /usr/local/Ascend/llm_model/set_env.sh
echo "LD_LIBRARY_PATH"
echo $LD_LIBRARY_PATH
echo "PATH"
echo $PATH
# 通过命令行参数来或者环境变量来更新mindie的配置文件
# 参数传给
python update_mindie_config.py "$@"
if [ $? -ne 0 ]; then
echo "[ERROR]生成mindie_config失败"
exit
fi
echo "启动mindieservice_daemon"
echo "日志请在查看 /usr/local/Ascend/mindie/latest/mindie-service/logs/mindservice.log"
cd /usr/local/Ascend/mindie/latest/mindie-service/bin/
# 启动推理
./mindieservice_daemon
# 此处原本想让mindieservice_daemon后台运行的,然后直接观察日志的。
# 但是这样程序如果崩了 容器可能不退出 不会自己重启 感觉不妥
# while true; do
# # 检查文件是否存在
# if [ -e "/usr/local/Ascend/mindie/latest/mindie-service/logs/mindservice.log" ]; then
# break # 文件存在,退出循环
# else
# echo "等待mindie-service写入日志"
# fi
# sleep 5
# done
# tail -f /usr/local/Ascend/mindie/latest/mindie-service/logs/mindservice.log
到此,容器内的自动化脚本就写好了
之后所有步骤都在宿主机上操作,不在docker容器中
保存镜像
将容器保存为镜像,我这里没有镜像还叫mindie,只是版本号增加了.made-by-lucent
# mindie-Qwen3-32B 是上个文章中启动容器时指定的名称
docker commit mindie-Qwen3-32B mindie:2.0.T17.B010-800I-A2-py3.11-openeuler24.03-lts-aarch64.made-by-lucent查看我们保存好的镜像

编写部署脚本
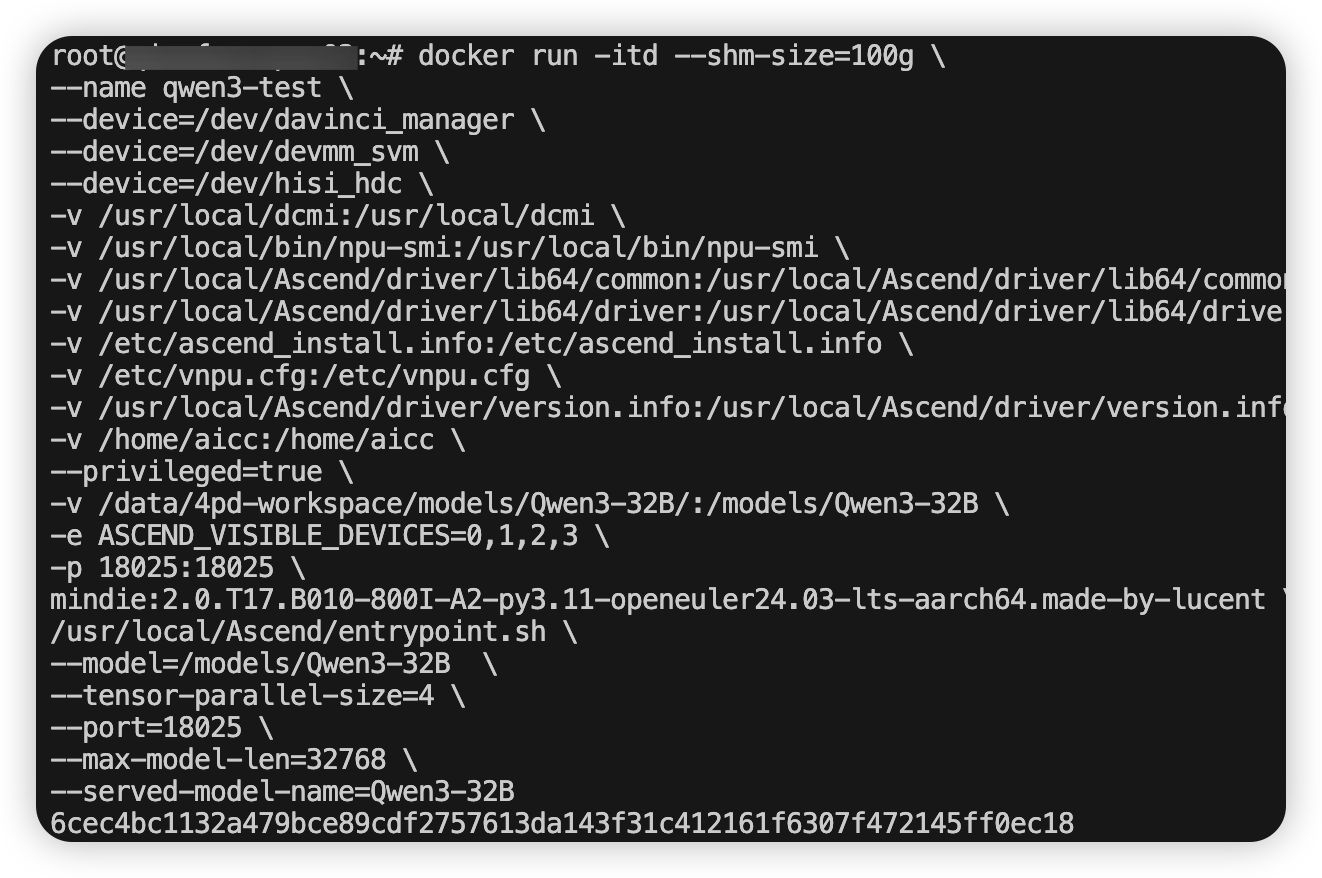
docker run -itd --shm-size=100g \
--name qwen3-test \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/common:/usr/local/Ascend/driver/lib64/common \
-v /usr/local/Ascend/driver/lib64/driver:/usr/local/Ascend/driver/lib64/driver \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /etc/vnpu.cfg:/etc/vnpu.cfg \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /home/aicc:/home/aicc \
--privileged=true \
-v /data/4pd-workspace/models/Qwen3-32B/:/models/Qwen3-32B \
-e ASCEND_VISIBLE_DEVICES=0,1,2,3 \
-p 18025:18025 \
mindie:2.0.T17.B010-800I-A2-py3.11-openeuler24.03-lts-aarch64.made-by-lucent \
/usr/local/Ascend/entrypoint.sh \
--model=/models/Qwen3-32B \
--tensor-parallel-size=4 \
--port=18025 \
--max-model-len=32768 \
--served-model-name=Qwen3-32B解释:
-v /data/4pd-workspace/models/Qwen3-32B/:/models/Qwen3-32B 映射模型权重文件 : 冒号左侧为宿主机路径,右侧为容器内路径
-e ASCEND_VISIBLE_DEVICES=0,1,2,3 指定卡,不使用 --device挂卡
-p 18025:18025 映射端口
/usr/local/Ascend/entrypoint.sh \
--model=/models/Qwen3-32B \ # 模型权重路径,对应上面权重映射路径的容器内部路径
--tensor-parallel-size=4 \ # 指定4卡推理,看你自己需要
--port=18025 \ # 推理端口
--max-model-len=32768 \ # 上下文长度
--served-model-name=Qwen3-32B # 推理服务的模型名称这是指定当容器启动后,直接执行容器内的自动化脚本,启动推理
测试
执行部署命令
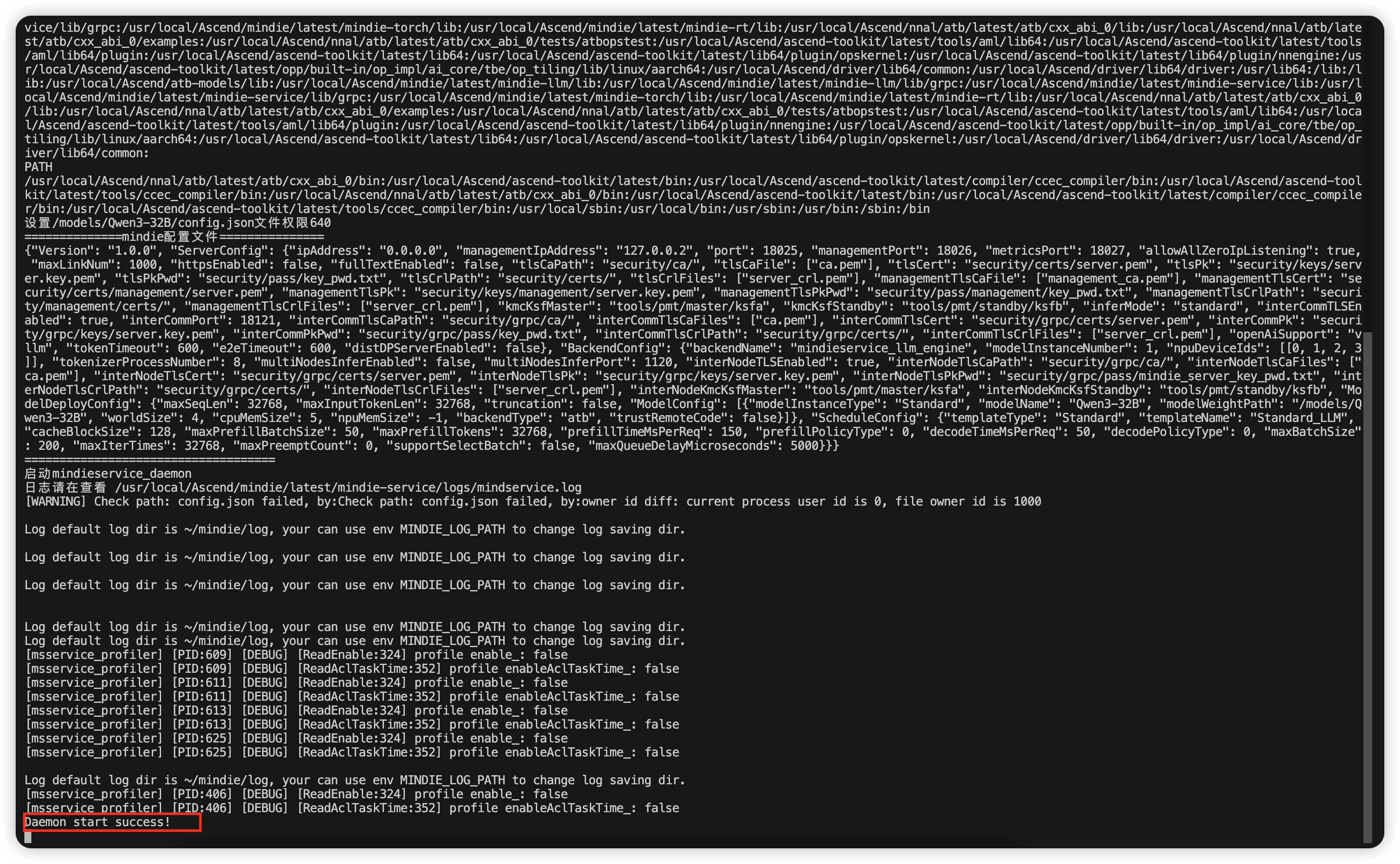
查看日志
docker logs -f qwen3-test我们可以看到,推理服务已经随着容器启动成功
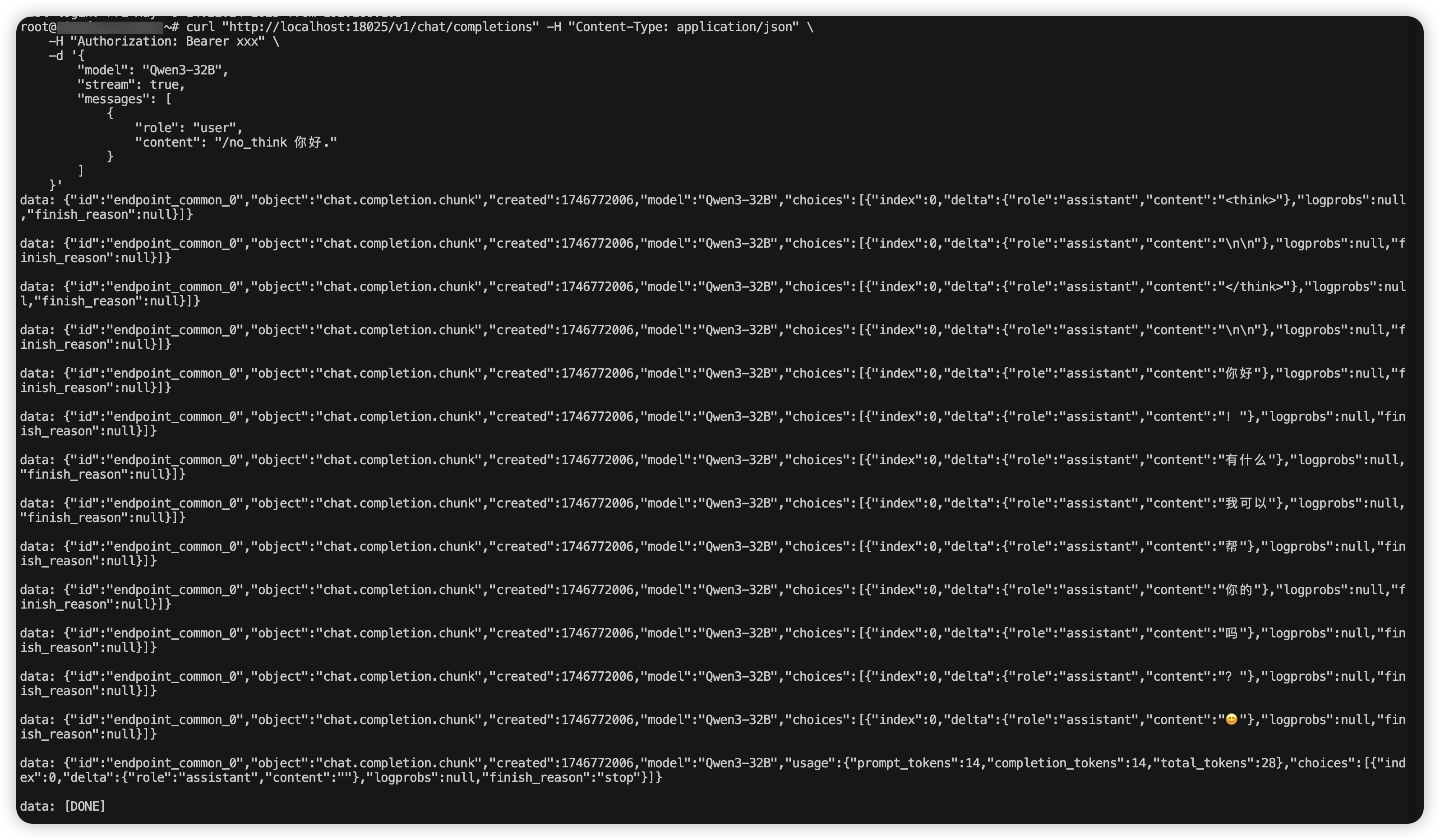
测试推理
curl "http://localhost:18025/v1/chat/completions" -H "Content-Type: application/json" \
-H "Authorization: Bearer xxx" \
-d '{
"model": "Qwen3-32B",
"stream": true,
"messages": [
{
"role": "user",
"content": "/no_think 你好."
}
]
}'
至此,一个使用更简单的推理镜像的封装就完成了,如果需要更换模型,只需要修改对应的参数即可。