实现效果
实现思路(Architecture & Design)
1. 系统目标与边界
目标:将任意常见音频/视频格式经转码为 16k 单声道 WAV → 做说话人分离(Diarization)→ 对每个说话人片段进行ASR 转写 → 轻量标点/情绪/语言修正 → 输出结构化分段结果。
交互形态:提供
同步 HTTP(小中型文件)
异步 HTTP + Redis(大文件)
WebSocket 流式(partial 增量 + stop 后完整结果)。
2. 核心组件与职责
输入层
POST /asr/diarize-transcribe:一次性上传文件;阻塞到结果完成后返回。POST /asr/diarize-transcribe/async+GET /asr/tasks/{task_id}:提交任务并立即返回task_id;后续查询 Redis 中的任务状态结果。WEBSOCKET /asr/diarize-transcribe/ws/stream:双通道(文本控制帧 + 二进制媒体帧);录音过程中周期性发送 partial 文本;stop后返回完整分离+转写结果。
音频适配与规范化
优先使用 ffmpeg 以管道方式将“任意媒体”转为 WAV(16k/单声道/PCM16);失败时回退 torchaudio。
对音量做轻量峰值归一化(目标峰值 0.9,最大放大 10x),提升 ASR 鲁棒性。
对多声道输入取均值转单声道。
工具函数:
wav_bytes_from_any_audio_bytes/wav_bytes_from_any_media_ffmpeginspect_audio:采样率/时长/RMS/峰值slice_wav_bytes:按时间窗口切片duration_seconds:获取总时长
建模层
ASR:FunASR
AutoModel加载iic/SenseVoiceSmall,负责将音频片段转文本。说话人分离:ModelScope
pipeline(task="speaker-diarization")加载damo/speech_campplus_speaker-diarization_common,输出{speaker, start, end}片段。后处理:
语言与情绪标签解析(从
<|...|>标签与文本特征推断)中文轻量标点修复(句末补全、口头禅逗号化、冗余标点压缩)
说话人归一化(将
SPEAKER_7→"8")
调度层
同步:串行流程:转码 → 分离 → 片段逐段 ASR → 组装返回。若分离结果为空,退化为整段 ASR。
异步:使用
ThreadPoolExecutor将核心流水线提交到后台线程;任务状态与结果存储在 Redis(queued/processing/done/error)。流式:
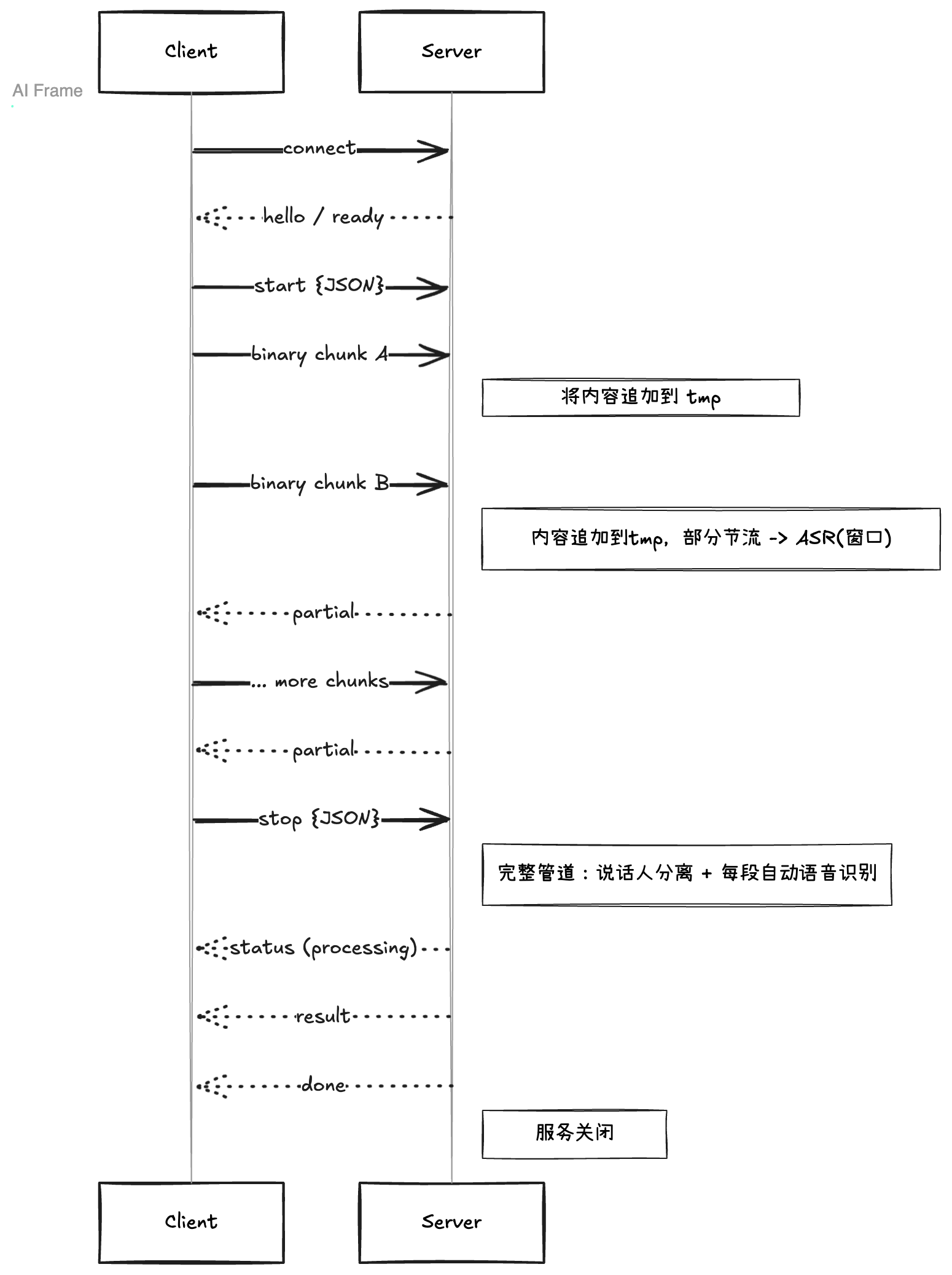
客户端
start后以二进制连续写入临时文件;服务端按字节增长推送progress。按节流策略(时间间隔 + 单任务互斥)从临时文件末尾截取窗口(默认 6s)做partial(仅转写,不做分离)。
客户端
stop后,将临时文件整体送入与同步/异步同样的完整流水线 → 返回result,随后done并关闭连接。
状态与存储
Redis 用于异步任务状态持久化:
{status, message, data, created_at, finished_at, meta},Key 为{REDIS_KEY_PREFIX}{task_id}。任务 TTL 可配置(默认 24 小时)。
3. 关键算法与数据流
3.1 说话人分离与合并
使用 ModelScope 分离输出若干
{speaker, start, end}片段;可能返回两种结构(spk或text兼容)。可选合并策略
merge_adjacent:当同一说话人相邻片段的时间间隙 ≤max_gap_s(默认 0.3s)时合并,减少碎片,生成更自然的段落。
3.2 片段级 ASR 与文本修饰
对每个分离片段调用
asr_sensevoice:拿到原始文本 + 标签(语言/情绪),再做轻量标点修复。
中文:去多余空白、对口头填充词做逗号化、句末补全
。/?。英文:若末尾无标点,补
.。
每段输出
DiarizedSegment:speaker, start, end, text, lang, emotion, prefix(emoji)。
3.3 partial 的窗口化思想
动机:在持续上传中给用户“接近实时”的文本反馈,减少等待焦虑,但避免频繁/高成本的整段计算。
做法:
不中断地向临时文件累积二进制数据。
按最小间隔
PARTIAL_MIN_INTERVAL_MS触发一次 partial 任务;取末尾 window(默认 6s)切片并做 ASR。不做说话人分离(分离需要遍历全局上下文,成本高、延迟长);以
speaker:"?"暂标。返回
{"op":"partial", "cursor": <累计秒数>, "data":[{...}]}
终止:收到
stop后再做完整分离+逐段 ASR,获得高质量结构化结果。
4. 三类接口的典型执行路径
4.1 同步 HTTP
读取 multipart 表单文件 →
rawraw→wav_bytes_from_any_audio_bytes(ffmpeg 优先)inspect_audio做自检与日志diarize_by_modelscope→ 若无结果,退化为整段 ASR;否则按(可选)合并策略生成片段片段循环:
slice_wav_bytes→asr_sensevoice→ 聚合为List[DiarizedSegment]返回
DiarizeResponse(success=true, data=...)
4.2 异步 HTTP
读取文件 → 生成
task_id→task_init()写入 Redis(状态queued)把
_run_pipeline_and_store(...)提交入线程池:流程与同步相同,结束后
task_update(... status="done", data=...)异常时
status="error"并记录message
立即返回
SubmitResponse(task_id=...)GET /asr/tasks/{task_id}轮询读取 Redis 状态
4.3 WebSocket 流式
握手后发送
hello提示客户端发
{"op":"start", ...}→ 服务端记录merge/max_gap_s→ 回ready客户端持续发送二进制音频块 → 服务端将其写入临时文件,周期发送
progress按节流触发partial:读取临时文件,窗口化转写 → 回
partial客户端发
{"op":"stop"}→ 服务端:回
status:processing读取临时文件全部内容 → 执行完整流水线 → 回
result→ 回done→ 关闭
5. 可靠性与失败处理
转码失败:捕获
subprocess.CalledProcessError,将 ffmpeg 的stderr透传到响应message中(HTTP 200 +success:false,便于前端统一处理)。WebSocket 体积保护:会话累计字节超
WS_MAX_MB(默认 200MB)即发送error并以1009关闭。Redis 不可用(异步接口):在提交阶段即返回
success:false+ 错误信息。partial 计算异常:只打印日志并跳过,不影响主循环与后续 stop 的完整结果。
清理:WebSocket 会话结束时确保临时文件
close + unlink,避免磁盘泄漏。
6. 性能与并发策略
线程池:
ThreadPoolExecutor(max_workers=WORKERS)用于异步任务主流水线
WebSocket partial 的后台计算(通过 http://loop.run
_in_executor);避免阻塞事件循环。
分段 ASR 并行:当前实现按顺序对分离片段做 ASR;在片段较多时可考虑并发(注意 FunASR 模型是否线程安全与显存/内存限制)。
I/O & CPU 混合:ffmpeg/torchaudio 解码、重采样、写入 WAV + ASR/分离模型推理均消耗 CPU/GPU;建议生产环境开启多实例 + 前置负载均衡。
7. 语义后处理策略
语言识别:优先解析 SenseVoice 标签;未命中时对文本做简单中文字符检测回落(中/英)。
情绪:由标签映射到
EMOJI_MAP,前端可直接展示prefix表情。中文标点轻修(
zh_light_punct):口头禅(“嗯/啊/哦/那个/就是/然后/那么”)后补逗号、折叠重复口头禅
去除多余空白、句末补句点/问号、压缩多连标点
英文:句末无标点时补
.
8. 可配置与扩展点
模型替换:
ASR 可替换为更大/更强的 SenseVoice 或其他 FunASR 模型(保持
asr_sensevoice接口不变)。分离模型可换成 pyannote 等(适配
diarize_by_modelscope输出结构)。
策略扩展:
合并策略可加入阈值自适应(基于能量/静音段时长)。
partial 支持关键字高亮或置信度;可维护一个增量缓冲做“微修订”。
稳定性:
将任务进度细化为百分比;在 Redis 中定期写入
progress字段。增加重试与熔断(尤其 ffmpeg 与模型推理)。
安全与鉴权:
前置 API 网关或在 FastAPI 中加入令牌校验;限制并发连接数与速率。
观测性:
加入结构化日志(请求 ID、task_id、耗时、模型延迟分布);Prometheus 指标(QPS、RT、错误率)。
9. 为什么这样设计(简要取舍)
ffmpeg 优先:兼容更多容器/浏览器产生的编码(webm/ogg/mp4 等);失败时回退 torchaudio 兜底。
partial 不做分离:分离需要全局信息、计算更重;partial 的核心诉求是“快”,因此只做末尾窗口的转写,保证低延迟与稳定节流。
异步用 Redis:跨进程/多实例共享任务状态简单可靠,TTL 控制清理,接口行为清晰(提交/查询解耦)。
轻量标点:避免引入额外 Punctuator 模型的复杂度与延迟,同时显著改善可读性;后续可无缝替换为更强的标点恢复模块。
10. 端到端时序(概念图,文本版)
WebSocket 模式(核心路径)